.webp)








.png)

Sales Leads
Trends in the Web Scraping Industry
The trends in the web scraping industry collectively shape the land...

Naman Gupta

Founder & CEO, Relu Consultancy




Most brands struggle a lot to stay visible on social media. Posts go out regularly. Ads run. Engagement numbers look encouraging on dashboards. Yet, when it comes to real conversations, the inbox often stays silent.
This gap frustrates many marketing teams. Likes rarely turn into questions. Comments may not convert into follow-ups. Manual outreach feels slow, and scaling one-to-one conversations across platforms feels unrealistic.
Direct messages sit right at the centre of this missed opportunity. They are personal by design, but difficult to manage consistently. AI-powered DM marketing helps bridge that gap, making it easier to start meaningful conversations before interest quietly fades away.
Public feeds have become crowded spaces. Sponsored posts compete with friends, creators, and trending content, often within a few seconds of scrolling. Even strong creative people struggle to hold attention for long.
Private messaging works differently. It feels quieter and more intentional. Users are more open to responding when communication is direct and relevant. According to Salesforce’s State of the Connected Customer, customers increasingly expect brands to understand their needs and engage with them in a personalised way.
This shift has changed how marketing performs. Instead of broadcasting messages to everyone, brands are learning to invite dialogue. Direct messages allow that exchange to happen naturally, one conversation at a time, without competing for attention in the public feed.
What makes DMs powerful is not just privacy, but context. Messages arrive in a space users already associate with conversation, not promotion. There is no audience watching, no pressure to react publicly.
This changes how people respond. Questions feel easier to ask. Curiosity shows up more clearly. Users who would never comment on a post may still reply to a message. Over time, these small exchanges build familiarity.
For brands, this means intent becomes visible earlier. Instead of guessing interest from likes or views, teams can learn directly from conversations. That clarity often shortens the path between awareness and action.
Smart DM automation is often misunderstood as mass messaging. In practice, effective systems work in the opposite direction. They focus on relevance, timing, and restraint.
AI analyses publicly available signals across platforms such as Instagram, Reddit, Facebook, X (Twitter), Pinterest, and YouTube. These signals include interaction patterns, content engagement, hashtags, and community participation. From this data, the system identifies users who are more likely to be interested in a specific topic or offering.
Engagement then unfolds gradually. Messages reference relevant interests. Likes and follows happen naturally. Links are shared only when context supports them. Nothing feels rushed.
Relu’s automation approach is built around this principle. Actions are paced, varied, and aligned with platform guidelines. The goal is not volume, but consistency. Not speed, but relevance. When done well, the automation stays in the background while conversations take centre stage.
One common concern around automation is the fear of sounding robotic. That fear is understandable, especially when automation is used without intent. Poorly designed systems often reinforce it.
Thoughtful automation does the opposite. AI handles repetition, but decision-making remains grounded in human logic. Message tone adapts based on platform behaviour and user response. When someone replies, the conversation slows down and becomes more personal.
This balance allows brands to scale outreach without flattening their voice. At the same time, teams regain time. Instead of manually tracking multiple platforms, marketers can focus on refining messaging, responding meaningfully, and learning from conversations as they unfold.
The impact of smart DM automation rarely appears overnight. In many cases, it becomes visible only after brands step back and observe how interactions change.
Replies feel more natural. Conversations last longer. Users ask follow-up questions instead of ignoring messages. Over time, these signals reshape how social channels are used.
Smart DMs allow brands to reach a large number of relevant users without sounding repetitive. Because outreach is interest-driven, messages feel selective rather than broadcasted.
This helps brands stay visible without adding to the noise users already filter out instinctively.
DM engagement grows through small interactions. A reply here. A question there. These moments create familiarity, which often leads to stronger responses later.
Private conversations also give users space to respond honestly, without public pressure or performance.
Direct messages reveal intent more clearly than likes or impressions. Brands begin to see which platforms support deeper engagement and which messages invite dialogue.
These insights come from behaviour, not assumptions. They help teams refine tone, timing, and focus with greater confidence.
Automation reduces repetitive outreach while preserving intent. Teams spend less time sending messages and more time responding thoughtfully.
Over time, this balance improves efficiency and results, without sacrificing authenticity.
The value of AI-driven DM automation becomes clearer when viewed through real-world application. In one such case, an automated DM tool was used to manage outreach across multiple social platforms without increasing manual effort.
Instead of relying on broad messaging, the system focused on identifying relevant user signals and initiating conversations where interest was already present. Engagement unfolded gradually, with messages and interactions paced to match each platform’s natural behaviour.
What stood out was the consistency. Outreach continued steadily across platforms while maintaining a human tone. Conversations felt contextual rather than forced, allowing brands to stay present without overwhelming users or violating platform norms.
This example highlights how AI-driven DM tools can support scalable outreach while keeping interactions relevant and compliant. You can explore the full case study here.
Social media engagement is steadily moving away from public feeds and toward private conversations. Direct messages have become a central space where trust forms and questions are asked.
AI-powered DM automation allows these conversations to scale without losing relevance or tone. When built responsibly, it supports personalisation, efficiency, and genuine engagement.
Tools designed with smart logic, like Relu’s, help brands stay visible while remaining aligned with platform expectations and real user behaviour.
Marketing today isn't just limited to being seen. However, it is more about being invited into a conversation. Brands benefit more if consumers spend more time messaging and reduce interactions with traditional advertisements.
AI powered direct messages enable communication without calling out for attention. Brands can develop trust, learn from their audience, and transform interest into enduring relationships by engaging in thoughtful interactions one at a time.
Conversational social media marketing is the future. AI automation can simplify large-scale conversations and benefit organisations.
Most people don’t struggle with understanding LinkedIn. They struggle with keeping up.
You log in with good intentions. You scroll for a few minutes. You like a post or two. Then work pulls you away. Days pass. Sometimes weeks. When you return, your reach feels lower than before, even though your profile hasn’t changed.
That drop is frustrating, especially when you know visibility comes from regular activity. Liking posts, commenting thoughtfully, staying present. The issue isn’t motivation. It’s time. Few professionals can realistically spend hours each week just staying active on LinkedIn.
This gap between knowing what works and actually doing it is where automation starts to matter. Not to replace effort, but to support it. When used carefully, smart tools help professionals stay consistent without turning LinkedIn into a daily burden.
As LinkedIn grew, so did the pressure to stay active. What once worked with occasional posts and manual comments now demands far more consistency. For many professionals, that expectation quietly became a source of stress rather than opportunity.
Daily likes, regular comments, and ongoing interaction help posts travel further on LinkedIn. Most users understand this. The challenge is sustaining it alongside real work. Engagement often slips between meetings and deadlines.
Over time, this inconsistency shows up as reduced reach and fewer meaningful interactions.
This gap between knowing what works and having the time to do it is what pushed automation into the spotlight. Early tools earned a poor reputation because they focused on volume over relevance. Spammy behaviour shaped how people viewed automation for years.
That perception still exists, but it no longer reflects how modern tools operate.
Today’s engagement tools are designed around context. Instead of pushing activity everywhere, they focus on where interaction actually makes sense. They observe patterns and identify relevant posts. Additionally, they support timely engagement, not forced.
The goal is not to constantly appear active. But it is to stay visible during the appropriate moments.
At its best, automation doesn’t replace authenticity. It protects it. Smart tools free up time for productive responses as they handle repetitive tasks in the background, leading to honest conversations.
Used carefully, automation becomes less about speed and more about consistency without burnout.
It becomes easy to remain active on LinkedIn when engagement is driven by specific intent. This is where trigger-based automation starts to feel useful, instead of overwhelming.
Instead of reacting to whatever appears in the feed, Triggify works around predefined triggers. These triggers can be keywords, specific profiles, or certain types of posts. When relevant activity appears, the system responds automatically.
The result is engagement that feels timely and aligned. You are present where it matters, without constantly monitoring the platform yourself.
Triggers help narrow focus. Rather than spreading attention thin across unrelated content, engagement stays connected to topics and conversations that match your goals. This increases the chance that interactions feel natural, not random.
Over time, this consistency improves visibility. People begin to recognise your presence around specific themes, which strengthens positioning without extra effort.
Triggify’s approach supports steady engagement without demanding daily manual input. By keeping actions human-like and compliant, it helps professionals stay visible while protecting their time and energy.
This approach is not just theoretical. It has already been applied in real working environments where consistency was difficult to maintain manually.
One such example can be seen in how Triggify itself was used to support steady LinkedIn growth through trigger-based engagement. By focusing on relevant keywords, profiles, and post types, the platform was able to stay active without relying on constant manual effort. Engagement remained aligned with intent, and visibility improved gradually over time rather than through sudden spikes.
The full breakdown of this approach is shared in this Triggify LinkedIn growth case study, which explains how automation can support consistency while keeping interactions natural and compliant.
Automation often sounds far more complex than it really is. In practice, most smart engagement tools focus on a few simple actions, repeated carefully over time.
One of the most common tasks automation handles is liking posts based on set conditions. These conditions might relate to keywords, industries, or specific profiles. Instead of manually checking the feed, the tool quietly tracks relevant content and responds when it appears.
This keeps engagement consistent, even when attention shifts elsewhere during the day.
Smart tools also help monitor activity across the platform. They scan posts daily and surface discussions that align with defined interests. This makes it easier to engage while conversations are still active, rather than joining too late.
Timing plays a big role here. Early interaction often feels more natural and visible.
Automation becomes most valuable when engagement needs to happen across many posts. Likes, light interactions, and profile visits can occur without feeling sudden or forced.
Well-designed tools spread actions out over time. This pacing helps activity appear natural and avoids overwhelming other users.
Compliance is built into thoughtful automation. Smart tools respect platform limits and behavioural patterns. They avoid aggressive bursts and follow predictable rhythms, which helps protect accounts from restrictions.
In the end, automation does not replace judgment. It replaces repetition. The human still decides where to focus and when to step in. The tool simply ensures presence doesn’t disappear when attention moves elsewhere.
For many professionals, LinkedIn growth still feels abstract. Post regularly. Engage more. Be visible. The advice is familiar, but the execution rarely fits into a busy schedule.
This is where engagement automation starts to matter beyond convenience. It supports personal branding in a way that doesn’t demand constant attention. Instead of reacting sporadically, professionals can stay present in conversations that align with their interests or industry.
Founders often use this approach to remain visible while focusing on building their business. Marketers rely on it to maintain steady engagement without splitting attention across dozens of profiles. Creators benefit from consistent interaction that reinforces their presence around specific themes.
What makes this shift important is balance. Automation works best when it handles repetition, not relationships. It creates space for human responses, thoughtful comments, and genuine follow-ups. When used with restraint, it supports credibility rather than replacing effort.
LinkedIn favours interaction over mere visibility. Professionals who combine intent with consistency tend to be the winners.
LinkedIn growth today depends less on posting volume. Moreover, it favours steady and relevant engagement. Staying visible no longer means being online all day. Trigger-based automation helps professionals interact where it matters most.
When engagement is guided by intent, it feels more natural and sustainable. Using innovative tools smartly supports consistency while leaving room for genuine interaction.
LinkedIn success does not come from working harder, but from working smarter. Automation, when applied thoughtfully, amplifies effort instead of replacing it. Tools like Triggify show how consistency and relevance can coexist without burnout.
As LinkedIn continues to reward meaningful interaction, professionals who balance smart systems with human judgment will be better positioned to grow, connect, and stay visible over time.
Most brands struggle a lot to stay visible on social media. Posts go out regularly. Ads run. Engagement numbers look encouraging on dashboards. Yet, when it comes to real conversations, the inbox often stays silent.
This gap frustrates many marketing teams. Likes rarely turn into questions. Comments may not convert into follow-ups. Manual outreach feels slow, and scaling one-to-one conversations across platforms feels unrealistic.
Direct messages sit right at the centre of this missed opportunity. They are personal by design, but difficult to manage consistently. AI-powered DM marketing helps bridge that gap, making it easier to start meaningful conversations before interest quietly fades away.
Public feeds have become crowded spaces. Sponsored posts compete with friends, creators, and trending content, often within a few seconds of scrolling. Even strong creative people struggle to hold attention for long.
Private messaging works differently. It feels quieter and more intentional. Users are more open to responding when communication is direct and relevant. According to Salesforce’s State of the Connected Customer, customers increasingly expect brands to understand their needs and engage with them in a personalised way.
This shift has changed how marketing performs. Instead of broadcasting messages to everyone, brands are learning to invite dialogue. Direct messages allow that exchange to happen naturally, one conversation at a time, without competing for attention in the public feed.
What makes DMs powerful is not just privacy, but context. Messages arrive in a space users already associate with conversation, not promotion. There is no audience watching, no pressure to react publicly.
This changes how people respond. Questions feel easier to ask. Curiosity shows up more clearly. Users who would never comment on a post may still reply to a message. Over time, these small exchanges build familiarity.
For brands, this means intent becomes visible earlier. Instead of guessing interest from likes or views, teams can learn directly from conversations. That clarity often shortens the path between awareness and action.
Smart DM automation is often misunderstood as mass messaging. In practice, effective systems work in the opposite direction. They focus on relevance, timing, and restraint.
AI analyses publicly available signals across platforms such as Instagram, Reddit, Facebook, X (Twitter), Pinterest, and YouTube. These signals include interaction patterns, content engagement, hashtags, and community participation. From this data, the system identifies users who are more likely to be interested in a specific topic or offering.
Engagement then unfolds gradually. Messages reference relevant interests. Likes and follows happen naturally. Links are shared only when context supports them. Nothing feels rushed.
Relu’s automation approach is built around this principle. Actions are paced, varied, and aligned with platform guidelines. The goal is not volume, but consistency. Not speed, but relevance. When done well, the automation stays in the background while conversations take centre stage.
One common concern around automation is the fear of sounding robotic. That fear is understandable, especially when automation is used without intent. Poorly designed systems often reinforce it.
Thoughtful automation does the opposite. AI handles repetition, but decision-making remains grounded in human logic. Message tone adapts based on platform behaviour and user response. When someone replies, the conversation slows down and becomes more personal.
This balance allows brands to scale outreach without flattening their voice. At the same time, teams regain time. Instead of manually tracking multiple platforms, marketers can focus on refining messaging, responding meaningfully, and learning from conversations as they unfold.
The impact of smart DM automation rarely appears overnight. In many cases, it becomes visible only after brands step back and observe how interactions change.
Replies feel more natural. Conversations last longer. Users ask follow-up questions instead of ignoring messages. Over time, these signals reshape how social channels are used.
Smart DMs allow brands to reach a large number of relevant users without sounding repetitive. Because outreach is interest-driven, messages feel selective rather than broadcasted.
This helps brands stay visible without adding to the noise users already filter out instinctively.
DM engagement grows through small interactions. A reply here. A question there. These moments create familiarity, which often leads to stronger responses later.
Private conversations also give users space to respond honestly, without public pressure or performance.
Direct messages reveal intent more clearly than likes or impressions. Brands begin to see which platforms support deeper engagement and which messages invite dialogue.
These insights come from behaviour, not assumptions. They help teams refine tone, timing, and focus with greater confidence.
Automation reduces repetitive outreach while preserving intent. Teams spend less time sending messages and more time responding thoughtfully.
Over time, this balance improves efficiency and results, without sacrificing authenticity.
The value of AI-driven DM automation becomes clearer when viewed through real-world application. In one such case, an automated DM tool was used to manage outreach across multiple social platforms without increasing manual effort.
Instead of relying on broad messaging, the system focused on identifying relevant user signals and initiating conversations where interest was already present. Engagement unfolded gradually, with messages and interactions paced to match each platform’s natural behaviour.
What stood out was the consistency. Outreach continued steadily across platforms while maintaining a human tone. Conversations felt contextual rather than forced, allowing brands to stay present without overwhelming users or violating platform norms.
This example highlights how AI-driven DM tools can support scalable outreach while keeping interactions relevant and compliant. You can explore the full case study here.
Social media engagement is steadily moving away from public feeds and toward private conversations. Direct messages have become a central space where trust forms and questions are asked.
AI-powered DM automation allows these conversations to scale without losing relevance or tone. When built responsibly, it supports personalisation, efficiency, and genuine engagement.
Tools designed with smart logic, like Relu’s, help brands stay visible while remaining aligned with platform expectations and real user behaviour.
Marketing today isn't just limited to being seen. However, it is more about being invited into a conversation. Brands benefit more if consumers spend more time messaging and reduce interactions with traditional advertisements.
AI powered direct messages enable communication without calling out for attention. Brands can develop trust, learn from their audience, and transform interest into enduring relationships by engaging in thoughtful interactions one at a time.
Conversational social media marketing is the future. AI automation can simplify large-scale conversations and benefit organisations.
Feeling overwhelmed by guest reviews? Discover the 5 clear signs your Airbnb business needs automation — and how Relu’s smart review management system helps hosts save time, boost ratings, and grow faster.
That’s how burnout begins.
Sarah, who manages four Airbnb properties, knows it well — she missed her daughter’s soccer game because she was replying to a 2-star review.
The emotional toll is heavy: checking your phone at dinner, refreshing the Airbnb app every hour, and losing sleep over one negative comment.
Hosts spend an average of 15–20 hours each week managing reviews manually. As your business grows, those hours multiply — while your free time, focus, and peace of mind vanish.
The truth? You can’t scale your hosting business while staying stuck in manual mode.
Here are five unmistakable signs it’s time to automate your Airbnb review management before it becomes overwhelming. And that’s where Relu comes in, helping hosts like Sarah save time by automating review responses, insights, and guest communication.
Every “quick peek” at your reviews adds up.
Between checking multiple platforms, replying, tracking, and cross-referencing, you lose 2–3 hours daily.
Jake, a six-property host, confessed:
“I check reviews before my morning coffee, during lunch, and before bed. It’s exhausting.”
Once you cross three properties, manual review handling becomes a time trap. Hosts who spend over two hours daily on feedback management hit a ceiling — they simply can’t scale.
Relu’s solution changes that completely.
Its centralized dashboard pulls every review from Airbnb, Booking.com, and Google into one place — so you respond once, not three times.
Hosts using Relu’s solution report saving 12–15 hours a week, scaling to 10+ properties up to 40% faster, and finally focusing on what matters most — their guests and growth.
Reviews aren’t just ratings but they’re business insights.
But when feedback is scattered across platforms, vital details slip through.
Small issues like weak Wi-Fi or leaky taps can quietly drag your ratings down.
Tom learned this the hard way: repeated AC complaints buried in Booking.com reviews dropped his 4.9 rating to 4.6 — costing him bookings and his Superhost badge.
That’s where Relu’s AI-powered sentiment analysis steps in.
It reads between the lines, identifying recurring pain points and opportunities you might miss manually.
Hosts using Relu’ solution recover an average of 0.2–0.3 stars in their ratings within three months — just by acting on insights they couldn’t previously see.
As soon as more than one person starts handling reviews, chaos creeps in.
Duplicate replies. Missed messages. Conflicting tones.
Without a system, teams waste hours each week figuring out who should respond and guests can sense the inconsistency.
Relu solves this with built-in collaboration tools that let you assign, approve, and monitor responses in real time.
Everyone sees what’s been handled, what’s pending, and what needs escalation.
Consistent, timely replies aren’t just efficient but they build trust. Hosts using Relu maintain a uniform brand voice and reduce guest confusion by over 70%.
Without structured analytics, hosts operate in the dark.
Manual tracking captures barely 20–30% of recurring patterns, leaving you guessing why one property outperforms another.
Are guests happier with your coastal apartment than your city loft? Is your cleanliness score dipping every summer? You can’t fix what you can’t measure.
Hosts who track review trends gain pricing power since properties with 4.8+ ratings charge 15–20% higher rates on average.
Relu’s analytics dashboard gives you that missing visibility.
It groups feedback by sentiment, category, and location — showing you exactly what guests love (and what needs fixing).
Hosts who use Relu’s insights often find patterns they never noticed before from seasonal dips to recurring mentions of check-in ease or decor.
Armed with data, they raise satisfaction scores, adjust pricing, and stay ahead of guest expectations.
Late replies, typos, and emotional responses happen, especially when you’re tired.
One poor response can go public instantly.
David, a California host, once replied defensively at 2 AM. His comment went viral and bookings dropped by 30%.
Relu prevents that spiral.
With tone-controlled templates, approval workflows, and scheduled responses, every message stays polished and professional, even under pressure.
Hosts say it best: “Relu keeps my tone consistent and my stress low. I never wake up worried about what I said at midnight.”
Manual review management doesn’t just cost time but also growth.
Quantifiable Losses:
Opportunity Costs:
Relu flips that equation.
With automation, hosts reclaim hours, increase their response rate, and unlock opportunities that were buried under manual work.
Relu’s solution isn’t just another review tool but an intelligent management system designed specifically for Airbnb and short-term rental hosts.
It centralizes every review, tracks sentiment, and highlights what matters most so you can take action before issues affect your reputation.
As one host puts it:
“Within two weeks, I stopped checking my phone obsessively. My rating went from 4.7 to 4.9 and I finally got my weekends back.”
Relu doesn’t just automate reviews — it amplifies your business and gives you your life back.
Within 2–4 weeks, you’ll notice faster responses, higher ratings, and more peace of mind.
Hosting should be fulfilling, not fatiguing.
Reviews are the heartbeat of your business, but managing them shouldn’t drain your time, energy, or joy.
Automation isn’t just a convenience; it’s the bridge between surviving and thriving in the hospitality space.
And Relu provides you that bridge. It is the all-in-one automation partner helping hosts regain control, enhance guest relationships, and scale sustainably.
Because in 2025’s competitive rental landscape, success belongs to the hosts who evolve —
those who choose smart systems over manual stress, and automation over anxiety.
If three or more of these signs sound familiar, it’s time to take the leap.
With Relu, you won’t just manage reviews —
👉 You’ll master growth.

Discover how healthcare organizations can save millions and improve care by adopting centralized data management. Learn from a real EMR migration case that proves how data centralisation enhances security, efficiency, and patient outcomes.
Imagine a hospital where every department operates in isolation — lab results in one system, prescriptions in another, and imaging reports buried in a third.
Now think of the confusion that happens when a patient walks in and the doctor doesn’t have access to their complete history.
That’s not a rare scenario — it’s the everyday reality for many healthcare organizations.
According to McKinsey, 20–25% of the total healthcare spending (nearly $1 trillion), is wasted annually due to inefficiencies, and up to $750 billion could be saved through better data utilization
The culprit? Fragmented patient data is spread across multiple platforms that don’t talk to each other.
The result? Lost time, redundant work, and compromised care.
But there’s good news — centralized data management is turning this story around.
Here are the five hidden costs of fragmented patient data that quietly erode the performance and reliability of healthcare organizations.
When clinicians can’t access a patient’s full record, they often repeat tests that have already been performed. This duplication may seem minor, but across thousands of cases, it becomes a massive hidden expense.
The average duplicate rate for a single hospital is between 5-10%. Healthcare organizations that create just 5 duplicates daily spend $78,000 a year on hidden operational costs at $50 per duplicate pair. Fragmented data doesn’t just waste money — it damages confidence between patients and providers.
Every disconnected system adds an extra step for staff. Healthcare professionals often spend hours reconciling mismatched data, re-entering information, or chasing missing details.
These inefficiencies create a ripple effect — longer patient queues, increased staff frustration, and reduced focus on clinical priorities.
Incomplete or inconsistent data can directly impact patient safety. Without access to accurate medical histories, healthcare providers need to make decisions based on partial information.
When patient data is fragmented, every handoff becomes a risk point — increasing the likelihood of human error and clinical oversight.
Data fragmentation doesn’t just slow operations — it weakens security. Every disconnected database is another door left open for potential breaches.
Beyond financial loss, breaches cause lasting reputational damage and patient distrust, both of which are harder to repair than any balance sheet.
Behind every healthcare system lies a patchwork of outdated technologies.
Managing multiple platforms consumes resources that could otherwise drive innovation.
This hidden cost isn’t visible on a balance sheet — but it silently drains both financial and human capital across the organization.
Fragmented patient data isn’t just an operational nuisance — it’s a barrier to safe, efficient, and intelligent care. Centralized data management solves this by connecting every record, report, and insight into a single, secure environment, transforming scattered information into a continuous, actionable flow.
By linking systems, departments, and locations, hospitals can eliminate inefficiencies, reduce risk, and empower smarter decisions — turning data into a true asset rather than a source of waste. Here is how….
Why it matters: When patient information is scattered across systems, duplication, delays, and errors are inevitable. A unified record connects all data points, giving clinicians a complete, accurate view of each patient.
Impact in Action:
A single source of truth creates a connected foundation, ensuring every interaction is precise and every patient is safer.
Why it matters: Manual data entry and reconciliation break up workflows and consume hours of staff time. Automation links disparate systems, cleaning, validating, and standardizing records so teams spend less time chasing data and more time on care.
Impact in Action:
Automation connects workflows across departments, transforming staff from data wranglers into patient care champions.
Why it matters: Fragmented systems slow collaboration and decision-making. A centralized database links clinicians, departments, and facilities in real time, giving every provider an accurate, current view of patient information.
Impact in Action:
Real-time access ensures data flows continuously, shifting healthcare from reactive to proactive.
Why it matters: Scattered data weakens security and compliance. Centralized cloud storage connects access, monitoring, and encryption, making protection an integrated part of the system.
Impact in Action:
Centralized security links protection and accessibility, turning safety into a built-in strength rather than an afterthought.
Why it matters: Outdated, disconnected systems slow innovation and inflate costs. Centralization links operational processes and analytics, giving hospitals a single platform for insights, predictive care, and digital transformation.
Impact in Action:
That’s the true power of centralized data management: connection in action, transforming fragmented healthcare into a seamless, intelligent, patient-centered system.
What was once a web of disconnected systems became an intelligent, secure ecosystem that put patients at the center of every decision.
In healthcare, information is life. And when that information is fragmented, the consequences ripple through every corner of the system — from clinical safety to financial health.
Data centralisation isn’t merely an upgrade; it’s a transformation.
By uniting data into a centralized database, healthcare organizations can:
Centralized data management transforms scattered systems into a synchronized network of knowledge — one that saves time, money, and ultimately, lives.
In an age where every second counts and every decision matters, data centralisation is not just about managing information — it’s about empowering action.
Because the true measure of a modern healthcare system isn’t how much data it holds, but how seamlessly that data connects people, purpose, and care.
The sports betting industry is evolving at a faster rate. Users’ expectations are constantly growing, warranting the need for technological support. Bettors today expect instant access to live odds and seamless transactions as quickly as possible. The need of the hour is a platform that never misses a pulse.
Robot Automation has proved to be a game-changer in online betting. It is capable of preventing a system glitch, which can result in the loss of valuable opportunities for both the operator and the bettor. Robot Automation confers betting platforms the required speed, accuracy and efficiency.
Robot Automation is the key to staying ahead in the competitive online betting market. Let’s explore how robot automation is transforming online betting and the benefits it offers.
Online sports betting is no longer just about placing bets. It’s a complex, high-stakes operation. Let’s look at the common challenges:
These pressure points make it clear: manual systems are no longer enough. Betting operators need tools that can think, act, and adapt faster than humans.
It’s essential to understand how betting bots operate before implementing robot automation.
Software programs designed to make informed decisions similar to humans are betting bots. They include:
These systems are modular. It means they adapt to different platforms and sports. Additionally, they are designed to be sneaky. They avoid getting detected using proxy rotation and randomised timing.
This automation upgrade helps users to scale their operations and eliminates the burden of manual effort.
Robot automation is changing the game by using software bots that combine real-time data with user-defined logic. They make decisions, take executive actions, and adapt to changing conditions. And all these without any human intervention.
Betting bots work similarly to trading bots in stock markets or crypto.
Here are the key benefits:
Robot automation isn’t just a tool! It’s a strategic advantage!!
Let’s look at a real example. Relu Consultancy tackled a major challenge in betting automation.
The problem: Betting platforms change frequently. UI updates, anti-bot measures, and CAPTCHAs make automation unstable.
Relu’s solution: They built a modular Chrome extension that automated betting across platforms like PS3838 and CoolBet.
Here’s how they did it:
The impact:
Relu’s case proves that robust, scalable automation is possible and already happening.
One of the most exciting aspects of robot automation is its easy accessibility.
Till yesterday, automation tools were under the dominance of developers and tech-savvy users. Today, platforms are designed with simplicity at their core. It has removed the need to write code or understand complex algorithms.
In the past, automation tools were reserved for developers and tech-savvy users. Today, platforms are designed with simplicity in mind. You don’t need to write code or understand complex algorithms.
Modern betting bots offer:
This shift empowers casual bettors, analysts, and small operators. It helps them compete with larger firms. Automation levels the playing field.
It’s not just about replacing manual work, it’s about unlocking new possibilities.
The power of automation goes beyond sports betting. Let’s explore how similar technologies are transforming other industries:
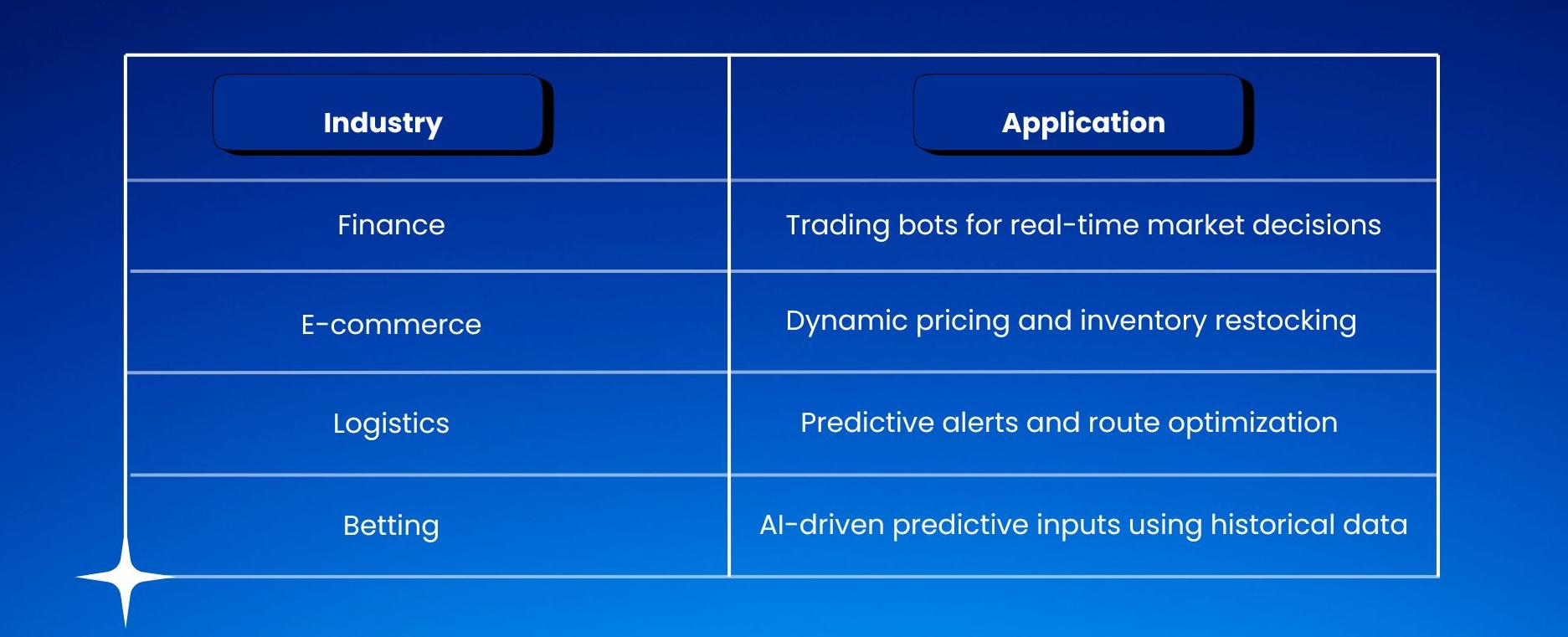
The future looks promising for betting automation. Let’s see how.
Betting bolts will become smarter, faster, and more accessible as technology continues to evolve.
If you wish to go with betting automation, choose a platform that supports bot integration. Define your betting logic clearly. Test your bot in a controlled environment before scaling.
Look for tools that offer:
Partner with experts like Relu Consultancy. They help you build a stable and scalable solution.
Automation hasn't remained only for tech-savvy users. With the right tools, anyone can benefit.
Robot automation in sports betting is no longer imaginative. It’s already happening and reshaping the industry.
Relu’s case study shows that real-world, scalable automation is achievable. Betting platforms adapting to this shift will gain a clear edge.
Here’s the key outcome: Automation isn't an option for industries needing speed and precision to scale revenue. It's mandatory.
If you’re still depending on manual workflows, it’s time to rethink your strategy. The future is automated. Are you ready to join it?
The fast-paced world of e-shopping automation has been the game changer. Businesses use automation to optimize operations from order processing to customer support. Product listing management is one area of automation that significantly impacts online e-commerce business. Automated product listing removes the role of manual data entry and offers error-free, seamless catalog updates.
At Relu Consultancy, we have worked with many e-commerce businesses to streamline their operations with custom automation solutions. Our expertise in automated product listing further supports businesses in terms of time, accuracy, and sales. Let’s explore the benefits of automated product listing and how Relu can help drive this automation smoothly.
Automated product listing is the process of automatically populating and updating the product catalog on an e-commerce platform. This system connects with inventory management, digital marketing tools, and pricing algorithms to ensure everything is accurate
This is done using spreadsheets or CSV files to upload multiple products simultaneously.
It includes integration of an API to fetch and update product details dynamically.
An automated sync process is implemented on platforms like Amazon, eBay, and Shopify.
Advanced automation tool with AI to optimize product descriptions, images, and keywords.
It is an old and evergreen process in which products are added individually after carefully screening and checking the details.
Manual product listing is time-consuming and prone to human errors. Automation support by Relu eliminates this need for repetitive data entry, reducing the risk of mistakes and ensuring that all the product details remain accurate across multiple channels.
Automated product listing ensures stock levels are updated in real-time. This prevents stockouts, overselling, and discrepancies between the e-commerce store and the warehouse. It also leads to better inventory control and customer satisfaction.
Automated systems optimize product descriptions and metadata to improve search engine performance. By using relevant keywords, structured data, and high-quality images, businesses can improve their online visibility and attract more customers.
Expanding to new marketplaces is easier than ever with automation. Businesses can quickly list their products on different platforms and reach a broader audience without requiring extensive manual input.
A well-maintained e-commerce platform has a catalog that offers a seamless experience. Automated listings ensure that product details, pricing, and images remain constant across all platforms. This improves trust and satisfaction among customers.
Product listing automation has been a game-changer for developing online businesses. By implementing automated product listings, enterprises get strong support to optimize their online presence and enhance customer experience. Various industries have benefited significantly from automated e-commerce listings. Below are some of the most beneficial industries that can leverage product listing automation for growth:
The retail sector is one of the biggest beneficiaries of product listing automation. Thousands of products, high customer demand, and stock updates will be handled seamlessly here. Moreover, the inclusion has simplified the inventory management process and improved online store operation.
The fashion industry operates differently and changes quickly with trends. Product listing automation helps fashion brands maintain their strong digital presence without the burden of manual listing management.
The fast-moving consumer food industry deals with a high volume of rapidly selling products. Automated product listing improves the efficiency of the process by managing frequent updates.
Automated product listing is crucial and time-saving for any e-commerce business. It improves efficiency, scalability, and accuracy. With automated e-commerce listing, businesses can effortlessly improve customer experience, inventory management, and expansion into new markets.
With Relu's expertise, specialize your business in custom automation solutions and explore the realm of growth in sales revenue with automated product listing.

Online shoppers today expect more than just a list of products - they prefer an online store that helps them find exactly what they're looking for. This is where dynamic product catalogs come in, transforming how e-commerce businesses connect products with customers.
By combining automation and technology with user-friendly design, these catalogs go beyond basic product displays and offer customers a seamless and engaging experience.
In this article, we'll explore the key features that make up dynamic product catalogs and how they benefit the e-commerce industry.
A product catalog shows everything customers need to know about your items, from descriptions and images to prices and specifications. In the digital world, these catalogs work like virtual storefronts, letting customers browse their entire selection from any device.
Unlike paper catalogs, digital versions offer interactive features that help shoppers find and learn about products more easily, making it simpler for them to decide what to buy.
A dynamic product catalog transforms your product display into an interactive shopping experience. So, when designing a catalog, make sure to include these essential features:
As online shopping continues to grow, dynamic product catalogs have become essential for e-commerce growth. Here's how these powerful tools can help your online store grow:
Today's online shoppers base their buying decisions heavily on product details. A Google Retail Study found that 85% of customers consider product information and images crucial when choosing where to shop. Without quality product information, you risk losing customers to competitors who provide better details.
A dynamic product catalog displays accurate, up-to-date information to create a smoother shopping experience. When products are properly indexed and searchable, customers find what they want faster.
The catalog can display personalised recommendations based on each shopper's behaviour, keeping them engaged and reducing the chances of them leaving your site without making a purchase.
Dynamic product catalogs improve both customer experience and your store's search engine rankings. These catalogs automatically handle product metadata updates - from descriptions and titles to categories.
This means your product information stays consistent across all pages, which search engines reward with better rankings.
Since the catalog optimises product tags and categories with relevant keywords, people searching for your products online can find your store more easily. And because these visitors are actively looking for what you sell, they're more likely to buy when they reach your site.
For instance, we helped Executive Advertising, a leading promotional products company, build a dynamic catalog. Our system ensures their extensive range of product information- from apparel to electronics is shown in a standardised way, making them easily discoverable online.
Dynamic product catalogs make it easier to boost e-commerce sales by showing customers relevant product recommendations at the right time. It uses customer data like browsing history and past purchases to suggest personalised customer recommendations.
When a customer views a product, the catalog automatically displays related items they might want to buy together, like suggesting a phone case when someone looks at smartphones.
For upselling, the catalog can smartly show premium versions of products customers are viewing. For example, if someone is looking at a basic coffee maker, they'll see higher-end models with extra features right next to them.
Dynamic product catalogs serve as a central hub for all your product information, making inventory management simpler and more accurate. When you update product details, stock levels, or pricing in one place, these changes reflect instantly across your entire online store, multiple sales channels, and internal systems.
This centralised approach helps your business in several ways:
Dynamic product catalogs represent a significant shift in e-commerce capabilities. By displaying product information in a more accessible, personalised, and engaging way, they help convert browsing into sales.
These catalogs enhance everything from customer experience and SEO rankings to inventory management and operational efficiency. Most importantly, they adapt to how people actually shop online.
For e-commerce businesses looking to grow, dynamic product catalogs aren't just a tool – they're an engine that drives sustainable growth through better customer experiences and smoother operations.
Partner with Relu Consultancy to get a catalog that optimises your product management and displays better revenue.
Managing your tasks and processes can get overwhelming, but the right automation tools can make things easier. With no code automation platforms, you don’t need to know how to code to create workflows that work for your team. Here are the key features to consider when choosing the best platform for your needs:
A good platform should be simple and easy to navigate. No code tools are designed for people who aren’t tech experts, so look for something with a drag-and-drop builder or a clear setup process.
For example, if you need to create a workflow for approvals or notifications, the platform should make it simple to connect tasks and set things up without frustration. Workflow tools with a straightforward design help you get started quickly and let you focus on your work instead of figuring out the system.
The best workflow automation tools connect with the apps your team already relies on. Whether you use email, spreadsheets, or project management tools, the platform should make it easy to link everything together.
For example, if your team uses Google Workspace or Microsoft 365, the platform should sync seamlessly with Gmail, Google Drive, or Teams. This way, your process automation tools can keep your tasks organized without extra manual work.
Starting from scratch can be intimidating, but platforms with pre-made templates make the process much simpler. These templates are pre-designed workflows for common tasks like sending reminders, managing approvals, or tracking progress.
For example, if you need a workflow to notify your team when a task is done, you can select a template, make a few adjustments, and have it ready in minutes. This feature is especially useful for beginners exploring no code automation for the first time.
Every business works differently, and your workflows should match your unique needs. The right workflow tools should let you customize workflows to fit your processes.
For example, you might need to route tasks to specific team members based on their roles or create workflows with multiple steps for larger projects. A flexible platform ensures your process automation tools can handle your team’s specific way of working.
Staying informed about what’s happening in your workflows is essential. A good platform should send notifications when tasks are completed, deadlines are approaching, or something needs your attention.
Tracking tools are equally important. Dashboards or reports showing which tasks are pending, completed, or delayed can help your team stay on top of their work. With reliable workflow automation tools, you can avoid bottlenecks and make sure everything stays on track.
As your team or workload expands, your automation tools should be able to keep up. Look for a platform that can handle more tasks, users, or workflows as your needs change.
For example, if your business takes on new clients or bigger projects, your workflows might need additional steps or more detailed tracking. A platform that grows with you ensures your no code tools stay useful over time.
When using process automation tools, keeping your data safe is crucial. Look for platforms that offer secure storage and protection for sensitive information, especially if your workflows involve client data or internal documents.
For example, if your workflows handle customer payments or private business information, security features like encrypted data storage can help you stay compliant and protect your reputation.
Even if a platform is easy to use, it’s always helpful to have access to support when you need it. Tutorials, FAQs, and customer service can make all the difference if you run into questions.
Some platforms also offer user communities where you can share tips, find inspiration, or troubleshoot issues. A supportive environment can help you get the most out of your workflow tools and discover new ways to improve your processes.
Not all businesses have the same budget, and the right workflow automation tools should provide a range of pricing plans. Look for platforms that offer flexible plans based on your team size and needs.
For example, a small business might start with a basic plan and upgrade as their requirements grow. Many platforms offer free trials, letting you explore their features before making a commitment.
In today’s fast-paced world, it’s helpful to manage workflows from anywhere. A platform with mobile access ensures you can check progress, approve tasks, or adjust workflows directly from your smartphone or tablet.
This is particularly useful for teams working remotely or for managers who need to stay connected even while traveling. Automation tools with mobile capabilities keep your workflows running smoothly, no matter where you are.
Finding the right platform for your workflows doesn’t have to be complicated. At Relu Consultancy, we specialize in helping businesses make the most of automation tools to manage their processes with ease. Whether you’re just starting with no code automation or looking for ways to improve your existing setup, we offer guidance to create workflows that match your needs.
Our expertise with no code tools, workflow automation tools, and process automation tools ensures you can connect your favorite apps, build custom workflows, and stay on top of your tasks without unnecessary stress. We’re here to help you organize and simplify your workflows, making your day-to-day work more manageable.
Ready to take control of your workflows? Get in touch with Relu Consultancy today, and let’s build tools that work for you.
Podcasting has evolved considerably since the term "podcast" was first coined by BBC journalist and The Guardian columnist Ben Hammersley nearly two decades ago in February 2004.
He combined the terms ‘iPod’ and ‘broadcast’ to define the growing medium. In 2005, Apple recognized the potential of podcasts and released iTunes 4.9, which integrated support for podcasts. Over the years, podcasts have become a popular form of media consumption.
32,158! That’s how many podcasts there are in India in 2024. Several factors have contributed to its growth, with AI being one of the biggest.
This blog will explore the current condition and future of podcasting in India.
India has become one of the biggest players in the global podcasting industry. So much so that the country’s podcast-listening market ranks third behind the US and China, with over 57.6 million listeners. Podcasts can be used for various purposes, including education, entertainment, business growth, etc.
Owing to its versatility, the podcasting-listening audience is expected to surpass 200 million listeners by 2025. However, several other reasons have contributed to the growth of podcasting in India. Some of these are convenience, the availability of diverse content, and increased accessibility.
Even the revenue of the Indian podcasting Industry is expected to reach $3,272.6 million by 2030, compared to $470.3 million in 2023.
Here are the key AI-driven trends that are shaping the podcasting industry:
There are several ways in which AI is driving revenue growth in the podcasting industry, with automation being one of the most effective ways. AI allows you to automate different aspects of podcast production, from editing to transcription and content recommendation. With AI, you can cut down on the time and resources needed to create podcasts. Reaching a wider audience has become easy through AI-optimized distribution strategies.
You can even personalize content based on listener data, increasing engagement and the potential to monetize your podcasts. Optimizing ad targeting and delivery with AI can help you attract more advertisers and command higher ad rates. Eventually, you can better align with brands for sponsorship opportunities with AI-driven insights about audience demographics.
If creating podcasts is a part of your business marketing strategy, you must use AI-powered podcast solutions for several reasons.
Let’s look at some common challenges and ethical concerns accompanying AI podcasting.
Here are some common ethical practices and mitigating strategies you can adopt to address these challenges:
The future of podcasts in India is closely tied to AI-driven solutions, and it looks quite promising due to the significant growth the market is expected to experience. There are a number of reasons behind this rise, including diverse content in regional languages, increasing listenership, and a growing demand for on-demand audio content. This will position India as one of the fastest-growing podcasting markets worldwide. There are predictions for a larger listener base and substantial revenue generation in the coming years.
The podcasting industry in India is at a pivotal moment, as AI is revolutionizing the way podcasts are created, distributed, and monetized. More podcasters are leveraging AI tools for automation, streamlining workflows, and enhancing efficiency. With advanced AI algorithms providing personalized recommendations, podcasters can now prioritize maintaining a deep level of engagement with their target audience over just reaching them.
The impact of AI on the podcasting industry will extend far beyond improving quality, reducing costs, and saving time. It will open new revenue streams and unlock limitless opportunities for growth and innovation.
Getting the right data about films, content preferences, and market trends is crucial for making informed decisions in the entertainment and media business. But with information scattered across countless websites, collecting it manually isn't practical.
AI-driven web scraping offers a smart solution that automates how we gather and organize online film data.
In this article, we'll look at what AI scraping is and how it can benefit professionals working in film and media.
AI data scraping combines artificial intelligence and machine learning to gather large datasets from the internet in a more efficient manner.
This advanced approach identifies, extracts, and organizes relevant data from websites by recognizing specific patterns in HTML structures or through API connections. The collected information, which includes text, images, videos, or metadata, is then systematically stored in databases or spreadsheets for further analysis.
As the entertainment industry becomes increasingly data-driven, AI data scraping offers several key advantages for film analytics:
AI data scraping has become essential for film industry professionals, from marketing teams to content creators. Here's how it helps across different areas:
Emotions influence decisions in the entertainment industry, making sentiment analysis an essential tool for industry professionals. They help filmmakers, writers, and others in the industry understand how viewers feel about their content.
With AI-driven web scraping, you can collect viewer opinions and reactions from diverse sources, including review websites and social media platforms.
By analyzing this audience feedback, you can identify what elements of your content connect most strongly with audiences. These insights help guide your creative and marketing strategies as well as future content development.
AI-driven scraping provides crucial insights into both theatrical and streaming performance metrics. It helps to extract and organize box office data on different films, making it easy to compare their success based on factors like genre, budget, and release strategy.
While it can be easy to assume which films might go hit, this data-driven approach often reveals unexpected trends about which genre will succeed financially.
Additionally, scrapers can gather valuable viewership data from streaming platforms focusing on audience preferences and consumption patterns across different distribution channels. Such comprehensive insights enable producers and investors to make more informed decisions about future projects and optimize their distribution strategies.
AI web scraping enables real-time monitoring of competitor activities in the film industry. It helps to scrape data on content performance, release strategies, and audience engagement. By analyzing this information, you can spot what your competitors are doing well, where they're falling short, and what gaps exist in the market.
With AI data extraction, you can also process genre preferences, demographic profiles, and cultural influences to identify emerging patterns and unmet needs like underrepresented genres.
As a film writer, gathering information about movies- from themes and character details to cast, crew, and production specifics is an essential part of your work. Web scraping tools can automatically gather these details from various websites and organize them in a structured format.
These tools give you access to both current details and historical content like past reviews, articles, and profiles that you can use as references in your writing.
Custom web scrapers take things a step further by extracting specific types of film information based on your needs. For example, if you're researching films centered around disability themes, the scraper can be configured to focus on films that match this criterion, making the data collection process more targeted.
AI scraper enables you to identify the most effective channels and audience segments by analyzing massive volumes of data across platforms.
By gathering data from social media (Facebook, Instagram, Twitter) and video platforms (YouTube, TikTok), marketers can see where target audiences engage most actively with content. This insight helps you allocate budgets to platforms that generate higher engagement, shares, and trailer reviews.
AI-driven tools also analyse demographics, behaviors, and interests from various platforms. This helps you tailor your marketing campaigns for specific groups like sci-fi enthusiasts for your upcoming space movie.
The film industry generates massive amounts of data across streaming platforms, theaters, and review sites daily. This is where AI data scraping changes everything.
Instead of drowning in spreadsheets and tabs, imagine having a smart system that automatically gathers exactly what you need.
At Relu Consultancy, we build custom scraping tools that work for your specific needs. Our tools grab the data you actually care about, so you can focus on making the decisions that matter.
Looking to make smarter, data-backed moves in the film industry? Our custom AI tools can help you get there.
Today's real estate decisions need more than just market knowledge and instinct - they need solid data. From daily property listings to housing market trends, there's valuable information hidden across different real estate platforms.
Data scraping helps you capture this information automatically and turn it into insights you can use. Whether you're an agent seeking the best properties for clients or an investor hunting for opportunities, real estate data scraping gives you a competitive edge in the market.
In this guide, we'll walk you through what real estate data scraping means, how it benefits your business, and the different ways to collect the data you need.
Data scraping uses software and bots to gather data from websites automatically. When a scraper requests information from a website server, it receives the requested page and then pulls out specific details like news, prices, or contact information.
In real estate, data scraping means collecting information from property websites, listings, and public records.
Using scraping tools, you can collect data from real estate sites like Realtor.com, Zillow, and government databases to understand market patterns, prices, and lucrative investments. Here's what real estate data scraping offers you:
This covers the essential details related to the property, such as its address and type, whether it is a single-family home, multi-family unit, condo or apartment.
Real estate data scraping also helps you find out the construction year, total square footage, and interior details like bedroom count, bathroom count, living spaces, and kitchen features. Its exterior elements including garage spaces, swimming pools, and other outdoor amenities.
The dataset shows each property's listing price - the initial amount set by sellers when their properties enter the market. It also offers information on price per square foot if it is available on the platform.
You can track the property's complete price history, including previous listing prices, price reductions, and increases over time.
Real estate data scraping reveals details about agents involved in property transactions. You can access agents' contact information, including names, phone numbers, email addresses, and office locations when they are listed. It also sheds light on agent ratings and reviews from past clients.
This data includes insurance details, loan history, and mortgage records of properties. You can also access area-specific information like average family income, demographic surveys, school ratings, and local crime rates. Additional records cover property tax assessments, current zoning laws, and building permit histories.
Here's how data scraping provides vital advantages in the real estate industry:
Real estate data scraping helps you spot market changes before they happen and plan your next steps. By gathering data on property prices, sales numbers, and mortgage rates over time, you can identify patterns and get a clearer picture of whether the market is headed.
Web scraping also tracks websites continuously, bringing in fresh data throughout the day - whether that's every few minutes, hours, or days, depending on what you need. Having this up-to-date information allows you to make decisions proactively, change your investment approach, adjust your property holdings, or choose the right time to buy and sell.
When listing a property, deciding on the right price is a complicated task that comprises a thorough real estate data analysis.
Data scraping pulls together details from many sources about similar properties in the area – everything from square footage and room count to amenities and market values. This complete picture helps you set fair prices that work for both sellers and buyers by showing you how similar properties are valued.
You can create a competitive pricing model, whether that involves going lower to get more buyer interest or higher to match the property's features and local demand.
Keeping an eye out for your competitors is essential to strategically positioning your business and attracting buyers. Through real estate data extraction, you can monitor competitor listings, pricing strategies, marketing campaigns, and customer reviews.
By scraping data from competitor websites, you see what works and what doesn't in their business. For example, if scraped data shows competitors' properties are selling quickly at higher prices, you might focus on investing or adjusting your prices there.
By pulling information from sites with reviews, rental listings, and occupancy rates, you can understand what properties are in demand. This data reveals current market rental values, tenant preferences, and property trends.
Such insights can help you make informed decisions about your rental portfolios to improve tenant satisfaction and reduce vacancy rates.
For instance, if your property data extraction shows a high demand for furnished units or pet-friendly properties in your area, you can adjust your offerings to match.
Understanding buyer preferences and behaviour is vital for tailoring marketing strategies and enhancing customer experience. Real estate data extraction can provide insights into what buyers value, like:
By analyzing these insights, you can better understand and provide what your buyers are looking for. This focused approach not only improves your closing rates but also creates better customer experiences by matching their exact needs.
Real estate data scraping helps identify active leads and potential clients. By monitoring forums, social media, and feedback sites, real estate businesses can find people who are seriously considering property transactions.
You can track their locations, preferences, and discussions to build detailed buyer profiles that make your lead generation more effective.
Real estate scraping tools eliminate manual data collection. Instead of agents spending hours searching different websites for property listings, housing market trends, and demographic details, these tools pull all information within seconds. This saves valuable time you can use for more important tasks like client meetings and deal negotiations.
These tools also remove human error risks by automatically collecting and organizing property data from multiple sources into structured spreadsheets for analysis.
Extracting real estate data helps spot profitable investment opportunities. By pulling data from different real estate platforms, you can find undervalued properties or up-and-coming neighbourhoods. This foresight can help identify areas likely to give good returns, leading to smarter investment choices and minimizing risks.
Developing your own real estate data scraper gives you complete control over data collection and processing methods.
While it requires technical expertise and regular maintenance, partnering with an agency like Relu Consultancy can get you a tailored data scraping solution that delivers exactly what your business needs.
You can tailor the scraper to extract data points specific to your niche, such as rental trends or luxury properties. As your business grows, you can adapt the tool, adding more features or targeting new markets.
Pre-built web scrapers let both technical and non-technical users pull data from any real estate website. These services handle complex issues like anti-scraping measures and proxy management automatically.
However, they may offer less flexibility and scaling options compared to custom-coded solutions. Pre-built web scraping tools come in three types:
Scraping APIs provide a direct way to collect data from websites that support this technology. These are pre-built interfaces that let you request and receive specific data from websites without needing to scrape their pages directly.
Instead of dealing with webpage structures and HTML, the method pulls data straight from the website's API, making the process more reliable and easier to manage.
By extracting and analyzing property data, you gain critical insights into market trends, property values, customer preferences, and competitor strategies. These insights help optimize everything from pricing and property management to lead generation and customer experience.
While data scraping offers powerful advantages, it's crucial to use it ethically and responsibly, following legal guidelines and respecting privacy standards. When implemented correctly, it becomes a key differentiator for real estate businesses.
Want to access data-driven insights for your real estate business? At Relu Consultancy, we create custom real estate data scraping solutions that deliver the comprehensive, real-time data you need to stay competitive in today's market.
Operational efficiency is essential for all businesses to succeed. Low code and no code workflow automation can help your business streamline operations and reduce repetitive tasks. Your employees feel empowered even when they have minimal technical expertise. Moreover, even non-developers can create complex workflows easily by using pre-built templates, real-time integrations, and user-friendly drag-and-drop features.
There are several reasons for businesses across different industries to use workflow automation, with increased productivity, fewer errors, and less reliance on IT teams being the most common ones.
Let’s find out how you can use workflow automation to your advantage, innovate, and stay competitive.
Low code or no code workflow automation tools enable you to create and automate tasks. Do you know what’s the best part about using no code automation? It’s as the name suggests. You don’t have to worry about writing long lines of code. Instead, you can either use pre-built templates or customize them to suit your needs.
You can also use drag-and-drop interfaces on workflow automation tools and software to quickly design and deploy workflows with little to no coding experience required. This enables you to automate, optimize, and streamline repetitive manual tasks, making processes smoother and more efficient. Low code automation, on the other hand, may require some coding to automate business processes.
Let’s look at some of the major benefits you can enjoy with low-code and no-code workflow automation.
Here are the major use cases of low code no code platforms for workflow automation.
Here are some factors you should consider when choosing a workflow automation tool.
Despite several benefits, no code workflow automation tools come with some challenges.
Low code and no code workflow automation is essential for your business to move forward as it breaks down barriers to technology. With workflow automation, your team can focus on more value-driven and strategic instead of manual processes that consume a lot of time. You can achieve improved accuracy, huge cost savings, and enhanced collaboration. Workflow automation tools are likely to get more advanced in the future, with AI-powered functionalities and integrations. If you want to achieve long-term success, workflow automation tools are indispensable because they can change the way you approach operational efficiency.
Drastically elevate your efficiency with Relu Consultancy’s process and no-code automation services. Cut out complexity and drive growth with our effective automation solutions. Get in touch with us to learn more!
In today’s business world, staying ahead isn’t just about having great products or services. It’s about knowing what your competitors are doing, keeping an eye on trends, and making smart decisions based on real information. Data is an indispensable tool. That’s where web crawling comes in—it’s a tool that helps businesses collect important data from all over the internet without needing to spend hours manually searching for it.
Let’s look at how web crawling can help with competitive analysis and market research, making it easier for businesses to stay in the loop.
Think of web crawling as sending out a digital assistant to explore the internet for you. These “crawlers” visit different websites, grab useful public data, and bring it back to you. For your business, this means you can easily track what competitors are up to, understand market trends, and get insights to make better decisions—all without constantly visiting websites yourself.
Web crawling works by systematically scanning pages on websites, following links, and collecting data like product prices, customer reviews, or blog posts. The best part is that this happens continuously in the background, giving you updated information whenever you need it. Whether it’s tracking a competitor’s pricing or gathering customer feedback, a web crawler online makes the data collection process simple and hands-off.
Keeping an eye on what your competitors are doing can be time-consuming, but web crawling makes it simple. Here’s how it works:
Web crawling isn’t just about watching competitors—it’s also a great tool for keeping up with your market. Here’s how businesses use it:
This data can help your business make smart, well-informed decisions and spot opportunities for growth. Web crawling offers a complete view of the market, helping businesses to stay flexible and responsive.
Web crawling can collect a variety of data that can be useful for both competitive analysis and market research, such as:
This data allows businesses to make informed, timely decisions that can boost their competitive edge.
Web crawling isn’t as complicated as it sounds. In fact, there are several tools available that make it easy for businesses to get started. Some of the popular options include user-friendly platforms that require little technical knowledge. These tools allow you to track competitors, gather market insights, and even crawl websites for keywords to keep your SEO strategy sharp.
Of course, web crawling isn’t without its challenges. Potential problems to be mindful of include:
Despite these challenges, with the right approach and tools, businesses can still gather significant amounts of useful data without running into too many roadblocks.
Web crawling is becoming more important as businesses shift toward more data-driven strategies. As technology evolves, web crawling will continue to offer businesses faster, more effective ways to gather insights. Whether it’s tracking competitors or exploring new market opportunities, web crawling will remain a vital tool in helping companies stay competitive.
Here’s how different industries can leverage web crawling:
Web crawling is an essential tool for businesses looking to stay ahead in today’s rapidly changing marketplace. Whether you’re using it for website competitive analysis or market research, it allows you to gather critical data that can shape your strategies and improve decision-making. With the right tools and approach, web crawling can be a simple, effective way to get the insights you need—without the manual effort.
Interested in seeing how web crawling can benefit your business? Reach out to Relu Consultancy today and discover how we can help you gather the data you need to develop customer acquisition strategies for success.
Contact Relu Consultancy to elevate your business and achieve new heights of success.
Today's era of digitalization has allowed businesses to tap into the strongest zone- the data. It is a goldmine of information that brings in tons of opportunities and growth to any business if used wisely. The key to unlocking data value is in data analytics.
Businesses find data analytics valuable to make informed decisions that boost efficiency, competitiveness, and growth. In this blog, understand more about what data analytics is, some relevant case studies, and how Relu has helped businesses with data scraping solutions.
To brief, data analytics is a process of collecting, and analyzing the raw data to extract valuable insights for the businesses to make relevant business decisions. Various techniques are put into place to make data analytics happen.
A process like data mining, business intelligence, and predictive analytics uncover a plethora of details relating to correlations within the data. By correctly using the insights, businesses can make data-driven decisions that will align perfectly with their goals.
Data Analytics is not limited to large organizations having massive datasets. It is the preferable for all type of businesses. They can use the data to optimize business operations, understand the customers better, and identify new opportunities.
Data Analytics plays a main role in shaping the company’s success and long-term stability. Some of the key benefits that contribute to the business growth include:
Some of the data analytics use cases that left a greater impact on the business:
Relu data analytics solutions team has helped multiple businesses and domains and out of all one of the standout successes was a prominent car wash company. Below is the brief on how Relu transformed its operations and business outcomes through data analytics:
A regional car wash company was operating in multiple locations. It was facing challenges in understanding business performance across multiple branches. They struggled to gain insights into revenue generation, customer retention, and labor efficiency.
They planned the comprehensive data analytics solution that catered to the specific areas-
The team integrated all the branches into a unified dashboard. This allowed the client to track everything on a real-time basis.
With the advanced data analytics tool, businesses now can track revenue streams from different branches and categorize payments. This helped in creating a clear financial report.
The data analytics tool also helped clients monitor the employee performance metrics like several hours worked, wash counts per employee, and feedback.
A customer analytics module was developed to track customer visit patterns and average ticket size.
Today, everything we do is based on data analysis. From buying the latest car model to finding a breakthrough in the industry to supercharge business profits, it is crucial to understand the data and gain insights from it. The collected data can uncover secrets that could potentially refine marketing and business strategies to take advantage of opportunities.
Imagine spending hours in front of your screen just to find the data that reveals industry trends or what’s in the minds of customers. You must have done that if you wanted to soar your business. However, it is a tedious and time-consuming process when done manually.
Data Scraping is an automatic way to extract data from websites to gather relevant information that can be later used for data analysis. This can be beneficial for rental car companies that want to know what type of car is in demand in the market.
For instance, one of the automotive car rental companies, VIP Gateway, used to extract rental car data from different competitor’s websites, including NAME.com, but manually. Let’s learn how web scraping tools helped our client overcome the cons of manually extracting data and saved their time and resources.
Regardless of industry, every company requires web data scraping services to stay ahead of the competition and scale its business in this economy. From dynamically adjusting service/product prices to finding trends to understand customer preferences, data scraping tools are specialized tools designed to accurately and quickly extract data from a webpage.
The car rental company extracted car rental data from competitor websites, one of which was NAME.com. This is a leading online platform in the United Kingdom that transforms how consumers discover and lease vehicles. It supports a wide range of filters, like Make & Model, Monthly Budget, Lease Duration and Type, Fuel Type, Body Type, Transmission, Color Preferences, and Features & Specifications, which allow customers to find their perfect vehicle conveniently.
The comprehensive set of filters, sub-filters, and sub-selections made it difficult for the client to extract the data manually. Each combination of filters provided different data, and if there is a large dataset included, then each result page needs to be visited manually to collect the data.
Also, nowadays, websites use JavaScript and AJAX for dynamic content loading. The data is only visible when specific filters are selected, so it is not immediately visible in the web source.
Hence, the client wished for a custom-built web data scraping tool that would efficiently extract data and take into account the different filter combinations.
The car rental company partnered with Relu Consultancy, a competent web scraping company, to help them automate this process. Hence, they set out a list of specific guidelines that helped our team to tailor the solution to meet the client’s needs and requirements. Here’s what the car rental company expected from the customized data extraction tool:
As a leading web data scraping company, here’s how our solution helped VIP Gateway to highly relevant industry trends:
The final Excel sheet provided extensive information about the vehicles that fell under the selected filter set. It comprised details like make, model, trim model derivative, finance type, and pricing for the first, second, and third positions and providers of the vehicles for the top three positions.
This streamlined the process of accessing vital data and transformed the manual and hectic web scraping process into an efficient data extraction process. Our customized solution helped the client handle the complexities of multi-level, multi-filter data scraping and simplified the labor-intensive process of manually extracting data from websites.
Web scraping offers ample advantages to businesses like car rentals, food services, and eCommerce websites, to name a few. These include:
Web scraping is important for organizations to make data-driven decisions in real time. Today’s world is all about making the right decisions at the right time to make the best of what time and opportunity have to offer to a business.
Are you looking for the best data scraping tools for your rental car business?
A leading web scraping company, Relu Consultancy, can provide data-driven solutions to numerous businesses. We offer myriad services when it comes to web extraction services, from custom API development and no-code automation to recruitment data optimization, and other data-driven solutions.
Grow and innovate your business by partnering with Relu Consultancy for all kinds of web data scraping solutions.
In the digitized world that we see today, there are a number of processes and advancements. One of the most powerful tools that businesses have identified for smooth work is the Application
Programming Interface or API. APIs for business help in different software applications to communicate, share data, and automate processes. Additionally, the usage of custom APIs helps businesses streamline their operations and reduce manual efforts.
This blog answers the critical role of custom APIs in transforming business processes and driving growth.
The importance of API integration in business processes is more than what meets the eye. Digital transformation or digitalization is no longer an option but a necessity. APIs allow disparate software systems to interact and enable seamless data flow between them.
Such an integration is crucial for businesses that rely on multiple software platforms for various aspects of their operations.
Let us consider an example to understand its importance. Consider a retail business using separate systems for inventory management, customer communications (CRM), and accounting.
Without API integration, data must be manually transferred between these systems, leading to potential errors and inefficiencies. In case of proper API integration, a person would have to manually transfer the same data to multiple systems.
Now, what are the challenges in such a system?
Unproductive use of time can have significant consequences for your business. However, with API integration in business, these systems are known to communicate properly and ensure that data transfer is smooth.
Hence, it reduces the risk of errors and saves time for a business that can be redirected for some strategic tasks.
Moreover, the integration of APIs in a business also helps it grow in scale. As the companies grow, the complexity of operations will increase.
By integrating cohesive API systems, businesses can grow automatically while removing fears of gaps in their software systems. Simply, we can say that your digital infrastructure grows in tandem with your business needs.
To enhance operational efficiency, you must integrate the role of API in streamlining business processes. Try out the custom APIs, which can automate a wide range of tasks easily, from simple to complex data transfers throughout multiple departments.
Take an example: in customer service, the API integration in business tends to help them proactively. The communication channels are merged across several platforms (email, social media, and others) compactly.
This helps the customer representatives working in the backend to facilitate a better conversation. Additionally, it helps them provide a more cohesive and responsive service than manual communications.
Moreover, API integration in business also plays a critical role in enhancing collaboration within an organization. It ensures that all the departments have unified data and fosters better teamwork.
Let us see some more examples:
For example, the marketing team can access the sales data for unified strategy making and execution, etc. This level of integration creates a more agile and responsive organization capable of adapting to market changes more swiftly.
In the finance sector, the APIs can help in automating the process of transactions. Traditionally, it would have taken multiple data inputs or entries, and it is an error-prone process, to be exact.
However, using the right API, transaction data can be automatically pulled from the organization's banking records and used as accounting records. You can call this an automatic accountant that serves your needs.
Using APIs for business comes with several positive aspects that arm-twists the modern organization to use their attributes.
In the next section, we are going to explore a real-life example of how the organization might use APIs for success.
The project was specifically made to address the challenges of product management for an E-commerce website. Jorick the founder of the bol.com, and gomonta.com needed a proper solution to solve the challenges of stock and inventory management.
The client was facing challenges related to managing the dashboard and get instant alerts regarding warehouse stocks. The manual approach to collecting and analyzing data did not provide accurate results.
It also introduced potential errors in the systems and provided improper results regarding low stock/stock out.
We developed a custom API solution, that helped in delivering accurate statuses. Our approach here was to provide a personal dashboard with real-time stock counts and alerts for low stock/stock out.
Additionally, it also helped in increased warehouse management and helped the client receive proper status updates regarding the warehouse stocks.
Warehouse management became easier for Jorick and he was able to manage his inventory in a proper way. The real time data generated helped him track the products which are in demand and make an appropriate strategy.
Looking forward, it is expected to a greater degree that usage of custom API for business will grow significantly. The importance of API will not subside when managing the processes of semi-to-large industries and companies.
Moreover, AI and machine learning integration into the systems are also going to help businesses thrive in the global technological environment. For example, we hope that custom APIs can be integrated into a company's CRM to help sales teams with predictive insights.
Machine learning algorithms can also be integrated into the supply chain management systems to optimize your inventory and reduce wastage.
The role of API for business is recognized to a greater extent thanks to the success it has helped companies achieve. Custom APIs tailored to perfection for a particular company are bound to streamline their processes.
Ultimately, it makes them versatile and allows digitally inclusive growth in this present century.
Investing in custom API development for your business not only improves customer interactions but also facilitates your internal working.
We can say that with API solutions from experts, you are basically future-proofing your business and catering to the opportunities lying ahead. Contact an expert today and get advanced business growth subscribing to relevant API services, today!
Today’s competitive landscape constantly revolves around operations and customer satisfaction. Car wash businesses have to work around smooth operations, excellent customer service, and revenue generation.
To make business run smoothly from different locations, data analytics is one of the advanced and proven ways. With the help of the right data analytics tools for car wash, owners can gain valuable insights about customer preference, can make data driven decision, and manage every step effectively.
Through this blog explore six must-have data analytics tools that car wash owners must know about to focus their business SEO scores and drive success.
Relu Consultancy offers custom data analytics solutions for car wash owners. Their solution offers advanced data analytics, industry-specific expertise, and business intelligence. With this combined solution businesses will get actionable insights to derive business growth and operational efficiency.
Advanced predictive analytics: this is the standout feature of analyzing historical data. This analysis helps businesses forecast future trends like revenue patterns, customer demand, and peak time.
Operation optimization: Relu Consultancy solution pinpointed inefficiencies in business. The analysis of service time, equipment usage, and employee performance data helps businesses identify the bottlenecks and areas of improvement.
Custom dashboard: A customized dashboard is provided to monitor key performance indicators in real-time and service efficiency of each unit of business. Custom reports can be generated to decide for different branches of business.
Google Analytics has been around for a long time now and is a cornerstone for any business having an online presence. This tool extracts detailed insights about your website traffic, user behavior, engagement ratio, and conversion rates. Businesses like car wash often find ways to find customers that interact with their website.
This CRM is an excellent tool that combines the two crucial areas of any business- customer relationship and operations. It is one of the most used tools because of its excellent marketing automation features. Car wash owners must use this tool to manage customer data from different locations, track interactions, and automate their marketing efforts.
Tableau helps businesses of all sizes in data visualization and analysis. It is one of the ideal data analytics tools for the car wash industry, knowing the complexity of the data the business has. This tool is well-known for its excellence in transforming raw data into an interactive and visually appealing format for better analysis and reporting.
Predictive analysis: Tableau’s advanced analytics enable the car wash industry to analyze future trends like peak service time and seasonal demand changes. This is a great help to plan the resources and ensure you have the right number of staff at the time of requirement.
Marketing effective: The right integration of data from marketing campaigns helps businesses make different strategies. With Tableau, you can observe how online ads, email campaigns, and social media are working in driving traffic to online and physical stores.
Customer behavior analysis: Tableau helps businesses understand customer behavior with their frequency of visiting websites, preferred services, and spending patterns. This data will help car wash owners make marketing strategies and tailor promotions to specific customer segments.
Power BI's robust business analytics tool helps car wash owners visualize data and share insights with key managers across different locations. It helps businesses to connect data from multiple sources and create a custom dashboard with detailed reports.
Data integration: Power BI can integrate a wide variety of data from Excel, database cloud services, and also from web analytics platforms like Google Analytics. For businesses like car wash, it means having all the data from different sources in one system.
Real-time analytics: Monitor your car wash business in a real-time. Know every branch's performance daily by referring to the dashboard. The refreshed dashboard will track metrics like daily sales, customer feedback, employee performance, and service time.
AI-powered data support: Power BI uses AI to help your business discover trends and anomalies in your data. It has a “Q&A” feature allowing you to ask natural language questions about your data and review answers in the form of visualization.
Staying ahead of the competition requires a data-driven approach and for the car wash industry right usage of data is important. The choice of data analytics tool will depend upon your business preference. However, to have a unique solution business must try the customized approach of Relu Consultancy. Their comprehensive approach helps car wash businesses thrive in a competitive market by offering the right services at the right time.
Take your car wash business to the next level with the right data analysis.
Businesses are growing tremendously with the data-driven approach with CRM systems as the heart of the process. The right data usage with the CRM is crucial to keep up with the results. CRM acts as the central hub here handling the data in terms of customer interactions, sales processes, and marketing automation. To unlock the CRM system's complete potential, integrating it with some powerful data extraction tools is paramount.
These tools pull valuable data from various resources, including documents, emails, social media, and directories into the CRM system. This integration then helps CRM to function to the next step. Having said this, let’s explore the other eight benefits of integration data extraction with CRM.
Data entry process automation is important to save most of the time. Manual entry is time-consuming and is prone to errors. To eliminate the risk, automation is required. Finding relevant data utilizing a manual process will cover the entire day, whereas automation of the data extraction process automatically captures and input data from various sources into their CRM. This not only saves a lot of time but also ensures data is accurate, updated, and relevant.
Data accuracy is the basis of any decision-making and successful operations. When data is accurate, the true state of business is reflected allowing the key members to make informed choices, and deliver better customer experiences. Before feeding data into the CRM the data extraction tools boost data accuracy by following this process:
A strong CRM system is the one having the most valuable data. Integration of data extraction tools makes the CRM wealthy of customer data from various sources. With this more comprehensive profile of each customer can be created highlighting preferences, behaviors, and interactions across socials.
As your business grows the volume of data increases. Integrating the entire set of data into the CRM gets rigid as every time it might not be possible to enter the data. Whereas, with the data extraction integration with the CRM, there will be scalability and flexibility to handle increasing amounts of data without sacrificing accuracy and efficiency.
Whether your business is expanding into new markets, launching new products, or acquiring more customers, data extraction tools can scale to meet the needs. Moreover, the tools are flexible to adapt to the changes in the business process, ensuring CRM continues to provide valuable insights.
The regulatory environment of business is changing and updating each day. Every business has to meet their steps with the regulatory environment for data management practices. Integrating data extraction with your CRM gives you the comfort of not remembering every compliance.
Your business will function efficiently by automating the regulations during the process of capturing the data. These tools automatically categorize the data as per regulatory requirements and also update them in CRM. This proactive approach to risk management and compliance protects the business from costly fines and reputational damage.
A positive customer experience is a key to business growth. By integrating data extraction with your CRM, businesses will get detailed insights about each customer's preferences, needs, and behaviors. Through this data, businesses can deliver more personalized and satisfying experiences to their customers.
Integrating data extraction with your CRM allows your business to automatically capture and analyze data points to your leads. Relevant information like interaction history, demographic information, and engagement levels will be provided. This data will help the business prepare lead-scoring models for the sales team to prioritize the most promising leads.
When your business CRM is updated with customer interactions and recent history, it gets easy to identify the patterns and trends that point to cross-selling and upselling opportunities. If data shows that a customer makes a purchase for a particular product in a particular month, the sales team can proactively offer a complementary product or service before that particular month. This targeted approach will just not increase the revenue numbers but also strengthen customer relationship with the business.
Integration of data extraction with your CRM benefits the business in countless ways and transforms the way of doing business. Right from streamlining the data entry to enhancing customer experience, this powerful combination provides the tools your business needs to survive in this competitive market.
Relu Consultancy ensures data extraction and CRM integration are implemented seamlessly so that you can focus on what matters the most- the growth of your business and delivering exceptional customer experience.
The number of cars purchased every year is significantly increasing leaving a remarkable impact on the carwash industry. Technology plays a pivotal role in this transformation by handling both the operations and marketing.
However, carwash owners still face challenges that indirectly affect their operational efficiency, profitability, and customer satisfaction. All of these can be resolved using data extraction tools. By leveraging this technology, carwash owners can enhance their bottom line and improve their performance every year. Through this blog, take note of the challenges that data extraction solves for the carwash business.
Challenge- Carwash owners often find it difficult to track revenue consistently across multiple locations. Manual entries or basic software systems will not help in revenue tracking. The traditional method of tracking can cause discrepancies, errors, and real-time visibility.
Solution- Data extraction allows you to automate the collection of financial data from various sources, like point-of-sale (POS) systems, customer transactions, and accounting software. The tool consolidates the data into a centralized system where owners can monitor revenue on a real-time basis and spot anomalies. This not only ensures tracking but also helps owners to take proactive action in financial management.
Challenge- Inventory management in a carwash business can be huge, especially when you have multiple locations and multiple products like replacement parts, cleaning agents, and waxes. The inaccuracy in management leads to stockout days, overstocking, and overspending of operational costs.
Solution- Relu Consultancy’s data extraction tools pull inventory data from all locations on a real-time basis. The extraction tool helps carwash owners automate tracking of inventory levels, reorder points, and usage rates. Historial and current data trend report is also provided which helps owners optimize their inventory management process ensuring real-time updates. This solution minimizes the cost, reduces waste, and prevents stockout situations.
Challenge- Labor efficiency is a common challenge as labor cost is a significant expense that cannot be reduced. Carwash owners will face challenges like understaffing, inefficient scheduling, and overstaffing. This leads to higher operational costs and reduced service quality. Without real-time data about labor patterns, like peak hours or productivity, it gets difficult to dedicate the right workforce to the right work, resulting in wasted resources and suboptimal customer service.
Solution- Data extraction is a powerful solution here as it gathers labor data from all the units and analyses labour-related data. This data is extracted from timekeeping systems, POS, and performance metrics. With this bulk data scraping, owners and managers can get detailed insights about employee productivity, labor efficiency, and where each one is good at. This allows businesses to make better decisions by placing the right staff at the right time. Labor cost is also reduced during the slow time of the business which can be used at the time of additional training and process improvements.
Challenge- Retaining customers is a challenge when you are not tracking what they like and dislike about your service. Most businesses struggle to gain points here because it gets very difficult to keep track of customer preference, behavior, and satisfaction levels. Without accurate data about customer interaction and feedback, businesses can't improvise and meet the market expectation level.
Solution- Data extraction addresses these challenges by providing detailed insights about customer behavior and their specific preferences. This collection of data includes loyalty programs, customer feedback, and social media interactions. Owners get the complete set to analyse trends and study to meet customer needs. To simplify, personalised promotions, customized service offerings, and targeted communication can be developed by using this data. Relu Consultancy extracts solutions from all the units to harness the power of customer data in the right direction.
Challenge- Equipment acquisition is a significant investment for a carwash business and any downtime due to maintenance can cause revenue and customer loss. Predicting when the equipment fails and scheduling maintenance is the critical challenge today for any carwash business.
Solution- Relu Consultancy data extraction solution integrates equipment management system via data extraction solution. This data extraction monitors equipment performance by collecting data from sensors, usage records, and maintenance logs from different locations. With this data analysis, carwash owners and key managers can predict equipment maintenance. This proactive approach helps businesses to reduce their downtime, repair costs and run smoothly.
Challenge- The Carwash business or be it any business has to comply with various environmental regulations to perform environmentally. While performing the operations compliance like water usage limits and chemical disposal guidelines often breaks. Adhering to these guidelines can get more complex especially while dealing with multiple locations.
Solution—Data extraction helps carwash owners by monitoring and tracking environmental challenges like water consumption, chemical usage, and water disposal. This tool also automates the collection and reporting of data to key members to ensure compliance with regulations and avoid fines.
Challenge- Carwash owners fail to use the complete potential of data as critical information is stored in separate systems that do not interact with each other. This lack of integration brings inefficiency, missed opportunities, and incomplete business understanding.
Solution- Data extraction breaks down these silos of data by consolidating it from various systems into a single, unified platform. This integrated approach solves the problem by giving a holistic view of the operations. Furthermore, this helps carwash owners to identify trends, make data-driven decisions, and explore more data insights.
The carwash industry is not a new entrant in the industry, hence facing challenges has always been in the story. Facing these challenges smartly with the right tools and strategies is new. The data extraction method resolves common yet important issues faced by car wash owners. Right from revenue tracking to operation handling, data extraction enables real-time support.
By using the expertise of Relu Consultancy, car wash owners can witness the full potential of data extraction. Relu is designed to offer customized data extraction solutions that extend the limit to meet your business unique needs. As the carwash industry evolves, it is paramount to embrace data-driven decisions.
Gone are the days when decision-making in the corporate realm relied solely on intuition and experience. Today, data is the driving force behind all their strategies and predictions. Peter Sondergaard rightly said, “Information is the oil of the 21st century, and analytics is the combustion engine.” We at Relu Consultancy stand by this.
Let's explore why data is the driving force behind the future of business and the indispensable role it plays in shaping strategies, decision-making, and overall success.
The future is undeniably intertwined with the evolution and utilization of data. From technological advancements and business strategies to societal improvements, data will continue to be a driving force in shaping a more connected, efficient, and innovative world.
The responsible and ethical use of data will be crucial in navigating the challenges and opportunities that lie ahead. From analyzing purchasing patterns to gauging sentiment through social media, businesses leverage data to gain a comprehensive understanding of their target audience. This invaluable information enables organizations to tailor their products, services, and marketing efforts to meet the evolving needs and preferences of their customers.
As businesses accumulate vast amounts of information through customer interactions, transactions, and operational processes, they unlock a treasure trove of insights. This valuable currency allows organizations to understand market trends, customer behavior, and internal operations like never before.
By understanding individual preferences, behavior patterns, and needs, businesses can tailor their products, services, and marketing efforts to meet the unique demands of each customer.
Analyzing historical data and real-time information empowers organizations to mitigate risks, identify opportunities, and optimize their strategies for better outcomes.
Additionally, in an era of increasing regulatory scrutiny, maintaining compliance is non-negotiable. Data helps organizations adhere to industry regulations, ensuring ethical and legal business practices.
Organizations can leverage their data assets by offering insights, analytics, or even raw data to other businesses or industry partners. This additional revenue stream can be a significant contributor to overall business growth.
In this data-driven era, businesses that recognize and prioritize the indispensable role of data will not only survive but thrive in an ever-changing landscape. The question is not whether data is important, it's how organizations will leverage it to shape their destinies in the years to come.
As industries become increasingly saturated, businesses are turning to innovative methods to gain a competitive edge. One such powerful tool is data scraping, a technique that has found a significant role in competitive intelligence.
Let’s explore how data scraping can be harnessed to gather strategic insights, analyze competitors, and ultimately gain a decisive advantage in the market By understanding the competitive landscape, businesses can make informed decisions, identify opportunities, and mitigate risks.
Data scraping empowers businesses to monitor competitors in real time, tracking changes in product offerings, pricing strategies, and marketing campaigns. By extracting and analyzing this information, organizations can adapt their strategies, identify gaps in the market, and respond swiftly to emerging trends.
Let’s look at a few aspects of competitive intelligence when it comes to tracking data :
In the ever-evolving landscape of business, staying ahead of the competition is crucial for success. Data scraping, when used responsibly, becomes a powerful tool for gathering real-time, actionable insights into competitors' activities.
By harnessing the potential of competitive intelligence through data scraping, businesses can make strategic decisions that position them ahead of the competition.
The trends in the web scraping industry collectively shape the landscape of the web scraping industry, driving innovation, addressing challenges, and influencing the way businesses extract and leverage data from the web. As we venture into 2024, it's crucial to explore the emerging user trends shaping the web scraping industry.
With the integration of artificial intelligence and machine learning algorithms, scraping tools are becoming more adept at handling complex data structures, dynamic content, and evolving website layouts.
As websites deploy stricter anti-scraping measures, users are adopting sophisticated proxy management techniques to circumvent IP blocking and detection. Proxy networks and IP rotation strategies allow users to distribute scraping requests across multiple IP addresses, mitigating the risk of being throttled or blocked by target websites.
Businesses are investing in custom scraping solutions tailored to their specific needs, including proprietary algorithms, data models, and scraping pipelines. This trend reflects the growing recognition of web scraping as a strategic asset
Rather than resorting to traditional scraping methods, users are leveraging APIs and web services provided by websites to access data in a more structured, reliable, and sanctioned manner. This shift towards API-centric scraping reflects a growing emphasis on collaboration
By simulating human-like browsing behavior, users are turning towards tools that enable users to access and extract data from even the most complex web applications. Data cleansing, normalization, and deduplication are becoming standard practices to ensure the reliability and accuracy of scraped data. Moreover, users are augmenting their datasets through enrichment techniques, integrating data from multiple sources to enhance their value
The case between LinkedIn and hiQ Labs is a significant legal battle concerning data scraping, the use of publicly available data, and the boundaries of internet regulation. Here's what happened This case set an important precedent for how data is treated on the internet, particularly concerning public vs. private data hiQ Labs, a data analytics company, scrapes publicly available data from LinkedIn profiles to provide services to businesses, such as predicting employee turnover.
LinkedIn, a professional networking site, sent a cease and desist letter to hiQ, claiming that hiQ's scraping activities were unauthorized and demanding that they stop accessing LinkedIn's servers for this purpose.
LinkedIn argued that hiQ's scraping of its site constituted unauthorized access, especially after explicitly revoking permission via the cease and desist letter. LinkedIn claimed that by scraping its website, hiQ violated the DMCA, which includes provisions against circumventing technological measures that control access to copyrighted works.
The dispute led to a series of legal battles, with the case eventually reaching the Ninth Circuit Court of Appeals. The court ruled in favor of hiQ, stating that the CFAA's "without authorization" provision did not apply to publicly available data on the internet.
The LinkedIn vs. hiQ decision is often referenced in discussions about the scope and application of laws like the CFAA and the DMCA in the digital age. It highlighted the tension between individual privacy rights and the interests of businesses in accessing and using data.

Craigslist is a popular online classified advertisement platform that allows users to post listings for jobs, housing, goods, services, and more. Craigslist uses terms of service (ToS) that explicitly prohibit automated access to its website, including web scraping, without prior authorization.
3Taps was a company that aggregated data from various online sources, including Craigslist, and provided it to developers through an API.3Taps argued that the data it collected from Craigslist was publicly available and should be accessible for aggregation and redistribution.
In 2013, a federal judge ruled in favor of Craigslist, granting a preliminary injunction against 3Taps. The injunction prevented 3Taps from scraping Craigslist's data. Later, in 2015, a settlement was reached between Craigslist and 3Taps, where 3Taps agreed to shut down its operations and transfer its assets.
Web harvesting, or web scraping, has become essential for businesses seeking valuable data insights in today’s digital landscape. As technology advances rapidly, the web scraping world is evolving. Exciting new innovations in artificial intelligence, data privacy, mobile platforms, APIs, real-time analytics, and customization are shaping how data will be harvested from the web.
One of the biggest game-changing trends will be integrating more artificial intelligence into web scraping tools. AI-powered scrapers can mimic human browsing behavior dynamically, allowing for more accurate, efficient, and reliable data extraction. These intelligent bots can seamlessly adapt to website changes, parsing complex page structures that would stump traditional scraping bots.
Businesses will benefit tremendously from faster and higher-precision data harvesting enabled by AI. With access to richer datasets, companies can feed powerful machine learning algorithms to gain more insightful analytics and make better-informed business decisions.
As web scraping becomes more pervasive across industries, businesses must prioritize ethical data harvesting practices. Issues around copyright, data privacy, and other legal considerations cannot be ignored. Scraping data without a website’s consent or scraping confidential user data can open companies up to lawsuits and seriously damage their reputation. We expect to see more scraping services like Relu Consultancy emerging, which make ethical harvesting a core priority in their business model. Only collecting data through proper consent channels and adhering to all guidelines will enable the web scraping industry to grow sustainably long-term.
Mobile devices now account for over half of all web traffic globally. As such, web scraping will increasingly shift towards harvesting data from mobile apps and mobile-optimized sites. Businesses recognize the enormous value in extracting consumer insights, competitor data, market trends, and other intelligence from the growing mobile sphere.
Specialized scraping tools for parsing mobile pages and apps will become standard. Companies proficient at mobilizing their data harvesting efforts will gain competitive advantages in their industries.
While scraping data directly from displayed web pages works, the future will see a rise in structured data formats and API integrations for more optimized harvesting. JSON, XML, and other standardized datasets allow for more controlled, consistent access to website data. APIs also provide a more direct path for scraping critical information.
Rather than parsing complex HTML, businesses can rely on clean, well-organized data transfers through structured feeds and APIs. This evolution will enable more reliable, efficient data harvesting at scale.
As Big Data analytics becomes more critical for businesses across industries, web scraping will play a huge role in aggregating massive datasets. Scraper bots can rapidly gather data from countless websites, apps, and online platforms – data that would take humans’ lifetimes to compile manually. Feeding all this harvested information into Big Data pools will allow businesses to identify patterns, trends, and unique insights that would be impossible to detect otherwise.
Web scraping will be a fundamental driver of wider Big Data strategies.

This is one of the web harvesting benefits. Many business decisions require analyzing the most current, frequently updated data possible. As such, real-time web scraping capabilities will be hugely valuable going forward.
Rather than running periodic scraping jobs, bots can provide live-streamed data as websites update information minute by minute.
Real-time scrapers allow businesses to monitor competitors, track market trends, and respond rapidly to industry shifts as they happen. This data immediacy will enable more agile, informed decision-making.
Every company has unique data needs from web harvesting. Point solutions tailored to these specific use cases will define the future of web scraping. Beyond one-size-fits-all tools, scrapers will be highly customizable – from the sites scraped to the datasets extracted.
Personalized scraping ensures businesses get the exact information they need from the web for their operations and analytics. Custom scrapers will provide greater utility and value as companies become more data-driven.
From AI to mobile platforms to real-time analytics, web scraping technology is advancing quickly to meet emerging business demands. As the world becomes increasingly data-centric, web harvesting will grow more critical for empowering better decision-making.
Best web harvesting service companies that embrace these innovations and trends will thrive in leveraging web data to maximum potential. With trusted, ethical providers like Relu Consultancy leading the way, the future of web scraping looks bright.
In this modern, fiercely competitive industry, being aware of price changes is essential for companies. Cost tracking permits organizations to make knowledgeable choices, spot patterns, and remain ahead of their competition.
Internet scraping, a method utilized for extracting information from web pages, has become a strong weapon for automatic price tracking. In this article, we’ll look into the pros of data scraping to monitor price watching. We will additionally give an easy-to-follow manual regarding the process of this approach efficiently.
Cost tracking has an important function in competition-driven pricing approaches. By keeping track of market prices, businesses can:
a) Optimize pricing: Frequently checking prices supports in spotting occasions to modify prices and stay competitive without losing profit margins.
b) Detect price trends: Examining past cost information allows companies to recognize trends and predict industry developments, including periodic ups and downs or price jumps.
c) Competitor analysis: Price tracking helps companies observe other businesses’ pricing strategies, detect pricing disparities, and place themselves strategically in the industry. It supports them in staying in the game and making pricing choices based on information.
Internet scraping involves a method that includes automatically gathering details from sites. It has become a popular method for price monitoring due to its numerous advantages:
a) Real-time data: Data scraping permits firms to obtain pricing details instantly. This guarantees that they possess the latest information for studying and making decisions.
b) Large-scale data collection: Using web scraping, you can gather price information across multiple websites concurrently, giving a complete perspective regarding the market and decreasing the requirement for manual work.
c) Customizability: Internet scraping enables companies to obtain particular information of importance, like the cost of products, discount offers, or product availability. That allows them to customize the details to their special monitoring needs.
To effectively implement web scraping for price monitoring, follow these steps:
a) Identify target websites: Find the sites that offer useful price details specific to your field. Think about like how popular, dependability, and if it is accessible the information you need.
b) Select a web scraping tool: Pick an internet scraping application that meets your wants. A lot of well-known selections include BeautifulSoup, Selenium, and Scrapy. Take into account such as the simplicity of use and how it supports your programming language. Your skill in dealing with evolving digital materials is crucial as well.
c) Build the scraper: Create an information gatherer with your selected application. Specify the information you want to gather, like goods names, costs, and links. Ensure your scraper can deal with possible obstacles, such as login prerequisites or CAPTCHA challenges.
d) Handle data storage and analysis: Decide how to keep and study the extracted data. One can use databases, Excel sheets, or specific data analysis programs. Your decision relies on the quantity and difficulty of the facts.
e) Schedule and automate scraping: Arrange a timetable to automate the web scraping process. That’s why the information is obtained regularly without any manual interference. Pay attention when extracting data from website regulations and boundaries to avoid potential legal or ethical dilemmas.
In order to maximize efficiency when monitoring prices using web scraping, remember these top tips in your thoughts.
a) Respect website policies: Always follow a site’s rules and regulations and information-gathering guidelines. Employ suitable HTTP headers, and adhere to the site’s speed limits or limitations.
b) Implement error handling: Web scraping might face problems caused by changes to the website, network problems, or inconsistent data. Create error-detecting systems within your web crawler to guarantee trustworthy information retrieval.
c) Monitor scraper performance: Frequently check the efficiency of your data extractor to detect and resolve any errors without delay. Keep an eye on scraping rate, information accuracy, and website layout modifications that could impact scraping.
d) Stay updated on legal considerations: Comprehend the legal consequences associated with scraping websites under the laws of your region. Make sure your data scraping activities follow according to applicable laws, which include safeguarding data and rights related to intellectual property.
Companies need to monitor rates to remain competitive, and Relu Consultancy understands this. Our best web scraping service in USA offers website scraping services for monitoring price trends and changes in the market. Our talented programmers can construct data extractors for gathering information from digital shops, online platforms, and other locations.
We employ natural language processing to guarantee precision and information uniformity. Our machines can offer everyday cost notifications to ensure you have the latest information. Using Relu Consultancy, you can be confident that the information about your prices is precise and current. Hire a web scrapper in USA today!
During the digital age, enormous lots of details are produced every moment. That creates it important for companies and scientists to collect important data productively.
Internet scraping has become popular as an effective way to retrieve content from websites. With new progress in AI, the domain has witnessed a notable revolution. This article explores artificial intelligence’s importance in gathering data from websites. That investigates what they are capable of and the positive aspects.
Internet scraping requires automating collecting information from webpages by examining the underlying HTML format. Usually, programmers write personalized scripts to gather certain sites. That caused the method to take up much time and be susceptible to errors. Nevertheless, data extraction has become easier to use and streamlined using AI technology. It allows people to get details from multiple online pages altogether.
Artificial intelligence-powered data extraction software uses AI algorithms to retrieve useful information from online pages smartly. These instruments can assess the hidden framework of a web page and detect trends to gather precise data.
Using methods like NLP and visual recognition, AI applications can explore complicated online pages and collect data from unordered structures such as pictures, PDF files, and written content. This skill enables quick and precise examination of vast quantities of data, allowing companies to create information-guided selections and acquire valuable knowledge.
Artificial Intelligence tools have changed data extraction through the introduction of cutting-edge methods. For example, specific tools use headless browsers that mimic human browsing. This enables users to engage with evolving websites that depend on JavaScript coding. This allows the retrieval of records that otherwise not be accessible. Smart computer programs also incorporate anti-blocking features. The systems guarantee continuous web scraping despite IP blocks and captchas.s.
This is the use of AI in web scraping. Artificial intelligence tools are not only good at data extraction but also contribute to enhancing data quality. By using artificial intelligence models, these applications can tidy up and make the data consistent. We can eliminate repetitions, rectify inaccuracies, and guarantee coherence. That leads to cleaner, trustworthy collections, improving the entire data evaluation procedure.
This is one of the web scraping benefits. Artificial Intelligence-powered website scraping software is created to handle large amounts of data. These allow people to extract details from numerous online sites all at once. Using multiple threads features, these tools can handle large data sets efficiently, greatly decreasing web scraping processing time. Automating tasks as part of artificial intelligence tools also eliminates the demand for hands-on involvement. That makes the procedure swifter and less prone to mistakes.
Just like every advanced tool, moral concerns are necessary in the environment of automated information gathering using artificial intelligence. People should comply with the terms established by website owners and guidelines and follow the regulations regarding data privacy. People must make sure when they gather tasks, must not breach any legal or moral limits.
Artificial intelligence tools have completely changed the web scraping industry, delivering unparalleled functionalities and performance. Using artificial intelligence algorithms, these tools facilitate smart data retrieval. We also utilize advanced data extraction methods and improve information accuracy. Thanks to scalability and automatic processes, Artificial intelligence-based web scraping tools are changing how enterprises and academics utilize information from the internet.
Combining AI and web scraping is a powerful tool for businesses and researchers. Relu Consultancy is uniquely positioned to assist with AI tools and their use in web scraping. The group with skilled experts is highly skilled in artificial intelligence and creating websites. This creates our ideal collaborator for enterprises aiming to utilize advanced tech tools.
We provide many different choices designed to match your requirements. We started with creating personalized AI software to maximize previously developed scraping tools. If you’re seeking automated information gathering or upgraded performance, our team can assist you in designing a productive solution.
We also aim to remain current on the most recent progress in ML algorithms and large data analysis methods. This guarantees that your resolutions stay at the forefront of technological advancement. Using Relu Consultancy, you can be confident that your artificial intelligence projects will get excellent service and loyal customer support for successful outcomes.
Understanding your competitors gives you a huge competitive advantage in the data-driven age. Getting and analyzing large amounts of data from your competitors’ websites with web scraping is automatic – giving you key insights in return. Here is a step-by-step guide to extracting competitor data using web scraping:
First, find out your main competitors who are in the market. Put their websites on a list and start prioritizing those from which you want to extract data. Next, go through their website and pull data points that would be valuable to come up with, such as:
Prioritize the most important data points to focus your web scraping efforts.
Next, you must understand how the data you want is structured on the page. Use browser developer tools like Chrome DevTools to inspect elements on the website.
Check the underlying HTML code and identify patterns for displaying the data. Consider elements like product listings, review sections, and blog posts. This will help you locate the right elements to target when extracting data.
Now it’s time to use a web scraping service to automate competitor data collection. There are many web scraping tools and data extraction services available. When choosing one, consider factors like:
A managed data extraction service in the USA like Relu Consultancy can be a great option since they handle your technical work and customizations.
Once you’ve chosen a web scraping tool, you can work on setting up the data extraction workflow. Most services provide options to configure scrapers visually without coding. You’ll identify the elements to extract data from based on the inspection done earlier.
Set filters to scrape only the data types you need. You may need to incorporate scrolling, clicks, delays, and other actions to access data for dynamic websites. Configure the scraper to scrape multi-page listings recursively.
Instead of a one-time scrape, you’ll want to collect updated data from competitor sites continuously over time. Most web scraping tools allow you to schedule and automate scrapers to run on a recurring basis.
You can have scrapers run daily, weekly, or at other intervals to get fresh data. The scraped data can be exported directly to databases, cloud storage, spreadsheets, or through API integrations. This enables fully automated scraping workflows.
Now the exciting part – using the extracted competitor data for insights! You’ll want to analyze and visualize the structured data to uncover trends, gaps, and opportunities for your business.
Some ideas include:
Advanced analytics can take competitor intelligence to the next level. The insights gained from properly utilizing scraped data can help shape your marketing, product, and operational strategies.
Websites frequently change their structure and design. This can break scrapers that are not maintained over time. Monitoring your scrapers regularly is important to check if they still function correctly and extract complete data.
When errors occur, the scraping workflow needs to be quickly corrected. This may involve tweaking selector elements, handling new page layouts, or accounting for other changes. A managed scraping service will take care of these revisions for you. Continuously monitoring and refining scrapers is key to sustaining competitor data pipelines.
Implementing an automated web scraping workflow for competitor intelligence gives you an edge. Following the steps outlined in this guide will help you successfully extract and leverage competitor data to make savvier business decisions. With the right approach, web scraping can be a valuable competitive analysis tool.
As a leading data extraction company, Relu Consultancy has extensive experience developing custom scrapers to deliver competitor insights at scale. Contact us today if you need help creating scrapers or analyzing scraped data!
E-commerce fraud is a huge problem that causes massive losses for online retailers. Fraudsters use sophisticated techniques like fake accounts, stolen payment info, and more to game the system. Luckily, web scraping provides a powerful tool to help e-commerce businesses detect and prevent fraud.
Some common types of ecommerce fraud include:
Web scraping provides an effective solution to detect and stop many types of ecommerce fraud:
Profile Analysis
Review Analysis
Coupon Hunting
Price Monitoring
Inventory Tracking
Payment Analysis
Here are some tips for implementing web scraping as part of your ecommerce fraud prevention:
Ecommerce fraud poses a real danger to revenues and reputation for online businesses. Web scraping offers a flexible yet efficient means of extracting data to identify threats and strengthen fraud prevention efforts.
Retailers can effectively mitigate emerging fraud trends and patterns using scraped data analytics. Scraping solutions tailored to your business provide maximum protection from online shopping scammers.
However, web scraping services in USA remain unknown to many retailers. You could benefit from engaging a professional web scraping firm and immediately exploiting its power.
In today’s highly competitive real estate market, having access to accurate and timely data can make all the difference in achieving success. With the help of web scraping services offered by Relu Consultancy, you can gain a significant advantage in collecting essential data to drive your real estate business forward.
Here are the top 5 tips for data collection for real estate:
Having comprehensive and up-to-date property listings is absolutely vital for real estate agents and investors. With web data scraping services, you can efficiently gather property listings from multiple sources, including:
This gives you a complete overview of the properties available in your target markets. You can easily analyze supply and demand dynamics, identify undervalued properties, spot pricing trends and conduct comparative market analysis. Automated web scraping saves an enormous amount of time versus manual collection.
In-depth market research is invaluable for real estate professionals. Web scraping tools allow you to gather demographics, economic indicators, growth forecasts, and other market trends from sites like:
Analyzing this data enables you to identify neighborhoods and markets with high growth potential. You can also determine what properties will be in high demand based on demographic factors.
Gaining competitive intelligence is key to staying ahead. Web scraping enables you to closely track the activities of other brokers/agents and real estate companies operating in your territories by collecting data from:
Monitoring this information helps you analyze their pricing strategies, uncover new geographical focus areas, and reverse engineer effective marketing tactics. You can use these insights to finetune your own business plans.
Due to the fast-paced nature of real estate, it is essential to have systems that provide real-time data. Web scraping tools offer automation to scrape and deliver the latest data continuously:
Access to this real-time intelligence ensures you can act swiftly on time-sensitive opportunities and gain an edge over slower-moving competitors. You are never caught off guard by sudden housing market shifts.
Understanding customer sentiments, needs, and pain points is invaluable. Web scraping enables you to compile customer reviews and feedback posted easily:
You can use these customer insights to improve service quality, address concerns, expand offerings, and build lasting customer relationships.
In conclusion, leveraging web scraping as part of a data collection strategy provides real estate professionals with invaluable business intelligence and strategic advantages. Relu Consultancy, a real estate data collection service, offers expertise in tailored web scraping solutions to extract data that drive smarter decision-making for your organization. Automate data gathering and unlock actionable insights today.
Web scraping is an automated way of collecting data from various sources like websites or computer software to benefit your business or clients. You might be wondering how web scraping works. Whenever you open a new website, you are often required to enter your details like name, e-mail address, and phone number. It is necessary to access the web further. This data is stored safely for security purposes. On the other hand, web scrappers automatically gather this information on their local sites. It might seem easy, but they work hard enough to take this information.
When you are running meta ads, web scrapping can be extremely helpful for reaching out to your potential customers. There are various companies providing web scraping services. Not every website is accessible to them. Some of the government and strict websites are not within their reach. Web scraping can be done through bots or web crawling. They store your passwords and store them in a private database. Developers do this work manually and help businesses provide information about their competitors. However, in previous years, many companies have been sued for illegally scraping data from websites without proper authentication.
Web scraping is a useful tool when you are running meta ads on platforms organized by meta like Facebook and Instagram. If you are looking for some way to enhance your marketing and advertising strategy, then you must give web scrapping a try. However, how would it upskill your product? Here are a few uses of web scraping:
If you want to have a glance at your competitor’s strategies and how they are working out their ads, you can scrap their data and make it benefit you. You can have information on their creativity, target audience, and their schedules.
Research:
Are you planning for some research before you set out to run your meta ads? Then why not do some research by using the web scrapping tool? You can assess the keywords that are in the search most. It will instantly help you reach out to more customers and attract them by running ads. In this way, you can capture the organic market as well.
Monitoring of performance:
Another way of using web scraping is to monitor the performance of the ads. You can indicate your key performances and get to know more about click-through rates. These rates are essential as they mark how many times your ad has been clicked by people. It will enable you to understand their interest as well.
Extracting product data:
When you are scraping data from other websites, you are taking a lot of their data and content. One of the most important is their efforts towards product and pricing. It will help you to leap over them. It can turn into a competitive advantage for you.
Improvising creativity:
If you are looking for some ideas or improving your creativity, then taking a look at the other’s creativity will be a bonus. Some information is available publicly but few can be obtained only by web scrapping.
Tracking ad inventory:
If you want to track the ad inventory, then web scrapping is a great source for it. You can also have access to detailed reporting where various performance reports are available. It would help you to track down the effectiveness of your ad compared to the ones by your competitors.
The information obtained from web scrapping can be stored in various forms like Python, etc. Since web scrapping is wide in scope, there are many things you must know about it before beginning. Relu Consultancy is one of the best web scraping service providers and takes high care for the protection of data.
Web scrapping is legal. However, you must obtain a license and you can access the public information. However, some data are under high protection which means you cannot scrape them. There are a few terms and conditions that you cannot violate. Scraping of information related to intellectual property is prohibited and can lead to illegality. As a consumer, you might be considering what if any sensitive information gets shared with the scrappers. Then you do not need to worry as explicit consent is required for using such information.
Since you have read the entire blog, we hope that your basic idea of what is data scraping and how it exactly works is clear. You can check out web scraping service providers in the USA. However, it can be a drawback as well. The way you can snatch content from others, they could do the same. The best way to be protected is to keep your data under high security. Not all information that you get will be reliable and will affect quality and authenticity. Henceforth, before getting into web scrapping make yourself aware of or consider APIs. So don’t wait and get your meta ads to reach your potential consumers.
Web scraping gives you access to the data stored in the websites. You can use these data to benefit and increase your business. But how can Google be utilized in scraping the website data? If that is a question, then here is the answer to it. Through Google, you can scrap data by web crawling or by web indexing. There have been various questionable remarks relating to the legality of web scraping. Web Scraping services make the scraping of publicly available information less challenging and do not pose many legalities. Assistance from a consultancy agency offering Web scraping services in the USA would avoid any unfortunate circumstances.
Google is one of the largest companies that have to deal with IT software every day. However, does Google also scrap data? And does it offer a scraping service? However, it does not directly provide you with the data, but there are various tools that one can use to scrap the website data while using Google.
Google Search:
One of the easiest ways one can scrap information through Google is from the Google search. You can simply type down the information you need and select from the dropdown options, that would provide you with the most information. You can search for any specific queries and it will be made available to you within seconds. You can also get a list of various website links for more specific information.
Google Search operators:
If you are well aware of the keywords to be put in while searching, then Search operators can be used efficiently. Through this tool, you can use combinations of words as well as symbols. It will enable you to narrow down the options, thus providing you with customized results. Coupling them up with other engines can give you better results. When you are led to the specific website as per your need, it will find you with filtered results.
Google API:
Application performing interfaces, can be used for extracting data. It is another method used by programmers for web scraping. However, limits have been imposed on the usage of APIs. It has restricted the search to any number of queries to an extent. This means that if you are looking for scraping entirely based on these APIs, then it might not be able to fulfill your search requirements.
Google Programmable Search Engine:
Another method widely used for scraping website data is Google Programmable Search Engine. It is designed especially for the programmers to obtain specialized information. It provides refined data searches. It is a free tool that people can use to create customized search engines for their purposes.
Above are some of the tools that Google has been providing the developers with. There might be some restrictions as to the number of queries raised. However, the information and data are likely to be accurate and updated. This will make the scraping more efficient and usable.
People generally tend to confuse the term web crawling with web scraping. Belonging to the same branch, they are somewhat misinterpreted in their meanings and utility. They are used interchangeably but are not the same. However, here are the following differences one can draw while considering them:
Meaning:
Web crawling is the process in which the tools are used to get an idea of the content and then build for their websites. On the other hand, web scraping is used for extracting data in large amounts to improve its own business.
Programmers:
The ones working on the web scraping are called web scrapers. The bots performing web scrawling are known as web crawlers or web spiders.
Functions:
Web crawlers visit various links, look into the content, and add them to the indexes. A web scraper takes a load of all the HTML links and then focuses on gathering the data. These data can then be downloaded in the format required.
Usage:
Web crawling is especially used in fields like generating SEO results, monitoring analytics, and website analytics. Web scraping is used generally in stock market analysis, generating leads, and comparison of prices.
Above are some of the comparison parameters used for web crawling and web scraping. However, in reality, both are useful for collecting data.
Coming to the end of this blog, you would have fairly got an idea of how web scraping of data works. However, you must be aware that the processes at Google are automated which restricts a person on certain parts that are out of the reach of programmers. They are strictly protected under the systems of Google. Web scraping at Google is much more difficult and complex than for any other. There are various legal guidelines when one is following data scraping. Being ethical and respecting these guidelines should be the core service of a scraper. One must consider the impact scraping could create on their website.
Cloud scraping is a way of web scraping through clouds. Web scraping services in the USA provide huge benefits to people. When web scraping is done via a cloud-based environment, it is known as cloud scraping. It is a branch of data scraping. Multiple platforms can be used for this purpose like Amazon web services. However, do the developers use the same type of application as for another type of scraping? Well, for cloud scraping they use cloud-based virtual machines. If you are looking for integration of the cloud scraping with others, then it is possible and you can analyze the data more efficiently. However, while scraping one must be mindful of the legal compliances.
Cloud scraping is considered one of the best ways of scraping. There are various benefits that a scraper can enjoy while cloud scraping. Here are a few of them:
Reliability: One of such reliable sources in scraping can be achieved from cloud scraping. It is highly recommended when you want to minimize your downtime. It ensures that the scrapers have consistent access to the websites. This makes information available within no time. One can rely on the data received completely.
Cost-effective: If you are looking for some cost-cutting while scraping and are tight on budget, then you can go for cloud scraping. It is comparatively low in price but there is a compromise on its quality. The best part is that you would have to pay only for the ones, you put to use. You can also reorganize the resources during the project.
Scalability: If you are dealing with high volumes of data and are looking to scale them without facing downtime, You must choose cloud scraping. You can make adjustments to suit your needs and requirements. If the servers that you are handling, are required to be reorganized, you can handle them much more efficiently. If you are looking to increase productivity, you may at the same time distribute scraping over various servers. It will engage them at once creating better results.
Storing of data: Cloud scraping enables you to store and maintain data. Once you are done collecting the data, you can store them easily through cloud scraping. There are various options like databases, and data warehousing where your data gets stored. It will not only provide the facility for storing the data but will keep it maintained while you focus on the scraping process.
Global reach: The Internet has connected various people all around the world. Through scraping you can reach out to the websites available all over. Data centers are available all over the regions of the world, which makes access to data easier.
All the above were some of the benefits that cloud scraping can offer. People have been amazed at the results one gets by cloud scraping. It is making the work simpler yet professional web scraping services can make the work better.
If you think that web scraping is easy and you can do it without getting caught, then you might be wrong. Various websites can recognize any kind of scraping. Some websites have adopted techniques to mitigate web scraping. Here are some methods by which websites can detect web scraping:
CAPTCHA: Various websites can detect automated web scraping by requiring the users to solve these CAPTCHA challenges. Any kind of unknown activity can be recognized through them.
Tracking: When there is some unusual frequency in the logins or logouts from the website. Any abnormality can help in tracking out the scraping process.
Blocked IPs: One such method used by the scrapers is employing other IPs when one gets blocked. They try to re-enter and access as proxies. However, websites block them and deny access.
Limiting requests: If a user places too many requests over a short span, it technically detects the bot. The website can cancel their requests or at the end block them.
If you are found overruling the guidelines issued by the websites and accessing to some private data, you can get blocked. Therefore, web scrapers use such methods in which their chances of getting caught or blocked are minimized.
In conclusion, cloud scraping can be a beneficial tool to scrape data while using cloud-based applications. It is one such method by which a person can increase their efficiency, and scale for more data. However, setting up cloud scraping tools can be complex and expensive too. If the website, you are trying to scrap from has restricted the scraping of data, then it will be able to detect the source easily. A major problem that you can face while scraping is the reliability of the information. They might not be updated or accurate which makes you waste time and money. Hence, before scraping consider all necessary factors.
Who would not be aware of a multinational e-commerce company like shopee? This company has excelled over the years. While being launched only 8 years ago, it has become one of the largest platforms where a customer can buy or sell their goods. It offers a diversified range of products like beauty, electronics, clothes, etc. However, one can use web scraping tools for doing Shopee data scraping. If it fits your data requirements, you can instantly get them scraped. Shopee scraping is one of the trending highlights due to its reach and sales. Web scrapers can get the product details, price, sales, and reviews extracted.
Shopee being one of the largest e-commerce platforms, has been on a list of scrapers to get useful data. It attracts thousands of customers and scraping them can give tonnes of data. However, here is the detailed process by which you can scrape data from shopee:
Identifying: The first step while beginning scraping the data from shopee, is to identify the data you require. As it is a huge platform, and there might be some data, that would not be useful for you as a scraper. Therefore, understanding your requirements and then working on them can save a lot of your time. A web scraping tool selection will help you create to make the process easy.
Filling the parameters: The next step comes where you can set the parameters to get the customized results. Since the amount of data available is huge, if you put in the customization, it will only give the information that might be necessary for you. For example, if you are looking to scrap data from AirPods, you can put in the exact details that will lead you to better results. After this, all you need to do is run the scraper.
Extract the data: At the third step once the scraper is ready to run, within some time it will create data that would be beneficial for you. The data that has been retrieved by the website is most likely to be accurate and updated. These data can be extracted from the shopee and used for analysis.
Storage: This step involves taking away the data collected and storing them on the platform you select. There are various formats like JSON, text, Excel sheets, etc., where you can store the data. They provide a structured way and are a reliable source for the scraped data.
Saving the data: In the last step, the data is to be saved and maintained. This will help you to make their use even after doing some more scraping. There might be a situation when you would want to integrate the data collected with the recent ones. Saving them will make it possible.
These are the steps that you can incorporate into shopee scraping. With the above 5 steps, you can scrape the data. However, you must keep in mind the privacy and legal compliances.
Are you done scraping, but when will you store them? Once the scraping process is completed, you need to store them in a structured format. This will help you to analyze the results and make a decision. These databases are responsible for not only storing purposes but also for maintaining them. Here are some ways in which you can store the data:
XML: This database is used to store data in the form of Extensible markup language. This software makes the sharing of data in other applications easy.
Text file: If you do not require the files to be stored in any structured or partly structured format, then you can use simple text files to store them. They are sometimes also referred to as plain text and you can use them for simple data storage.
Excel sheets: One of the common ways of storing data is EXCEL sheets. These are supported by Google and are a convenient platform for all types of data.
Cloud storage: The data gets stored in the cloud forms digitally. They are stored well with multiple redundancy options.
JSON: If you are looking for a database to store your complex files, then JSON is the one for you. It can store your temporary data in a good manner and you can use them for various programming languages.
Scraping of personal data in Shopee can be a task and one should adhere to respect these guidelines that have been issued by the company. If not, then it can create an adverse impact on your business. Next time you would want to scrap data to lead over your competitor in terms of pricing, marketing, or any other strategy, you can reach out to us. Shopee data is encrypted, and we can help you to get the best of the details required. Look no further, as we will provide you with the scraping services to fulfill all your requirements.
Our Testimonial



Terrance Wyatt -Founder & CEO

TCW Capital Finance


Daniel Matalon
Dando Online

Mohammad S - M
Airbnb Review v1.1

Olivier
Triggify

Hendrik De Haan
Hendrik De Haan

Bilal
Technical Team Lead

Tiago
EZIE

Kacper Staniul
Sponsorscout
Remi Delevaux
Eliran Shachar
Phil Albright
Tiago Vieira Alves
EZIE
Dib Guha
Aesthetic Record
BB Customer
Siri Gaja
Runa
Edwin Boris
CIO TechWorld
Antonio Romero
Ajeet Sing
Eric Hill

A21, E8 Extension, Tilak Nagar, Bawadiya Kalan, Gulmohar Colony, Bhopal, Madhya Pradesh 462039



